The Groovy language supports two flavors of metaprogramming: runtime and compile-time. The first allows altering the class model and the behavior of a program at runtime while the second only occurs at compile-time. Both have pros and cons that we will detail in this section.
1. Runtime metaprogramming
With runtime metaprogramming we can postpone to runtime the decision to intercept, inject and even synthesize methods of classes and interfaces. For a deep understanding of Groovy’s metaobject protocol (MOP) we need to understand Groovy objects and Groovy’s method handling. In Groovy we work with three kinds of objects: POJO, POGO and Groovy Interceptors. Groovy allows metaprogramming for all types of objects but in a different manner.
-
POJO - A regular Java object whose class can be written in Java or any other language for the JVM.
-
POGO - A Groovy object whose class is written in Groovy. It extends
java.lang.Objectand implements the groovy.lang.GroovyObject interface by default. -
Groovy Interceptor - A Groovy object that implements the groovy.lang.GroovyInterceptable interface and has method-interception capability which is discussed in the GroovyInterceptable section.
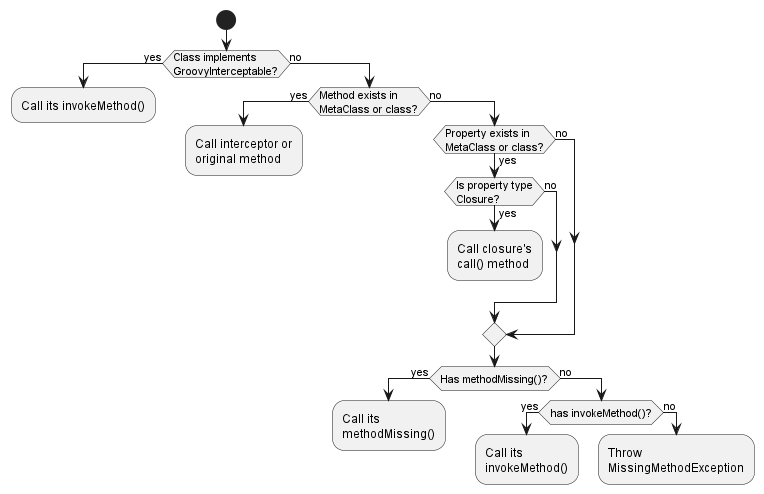
For every method call Groovy checks whether the object is a POJO or a POGO. For POJOs, Groovy fetches its MetaClass from the groovy.lang.MetaClassRegistry and delegates method invocation to it. For POGOs, Groovy takes more steps, as illustrated in the following figure:
1.1. GroovyObject interface
groovy.lang.GroovyObject is the main interface in Groovy as the Object class is in Java. GroovyObject has a default implementation in the groovy.lang.GroovyObjectSupport class and it is responsible to transfer invocation to the groovy.lang.MetaClass object. The GroovyObject source looks like this:
package groovy.lang;
public interface GroovyObject {
Object invokeMethod(String name, Object args);
Object getProperty(String propertyName);
void setProperty(String propertyName, Object newValue);
MetaClass getMetaClass();
void setMetaClass(MetaClass metaClass);
}1.1.1. invokeMethod
This method is primarily intended to be used in conjunction with the GroovyInterceptable
interface or an object’s MetaClass where it will intercept all method calls.
It is also invoked when the method called is not present on a Groovy object. Here is a simple example using an
overridden invokeMethod() method:
class SomeGroovyClass {
def invokeMethod(String name, Object args) {
return "called invokeMethod $name $args"
}
def test() {
return 'method exists'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.test() == 'method exists'
assert someGroovyClass.someMethod() == 'called invokeMethod someMethod []'However, the use of invokeMethod to intercept missing methods is discouraged. In cases where the intent is to only
intercept method calls in the case of a failed method dispatch use methodMissing
instead.
1.1.2. get/setProperty
Every read access to a property can be intercepted by overriding the getProperty() method of the current object.
Here is a simple example:
class SomeGroovyClass {
def property1 = 'ha'
def field2 = 'ho'
def field4 = 'hu'
def getField1() {
return 'getHa'
}
def getProperty(String name) {
if (name != 'field3')
return metaClass.getProperty(this, name) (1)
else
return 'field3'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.field1 == 'getHa'
assert someGroovyClass.field2 == 'ho'
assert someGroovyClass.field3 == 'field3'
assert someGroovyClass.field4 == 'hu'| 1 | Forwards the request to the getter for all properties except field3. |
You can intercept write access to properties by overriding the setProperty() method:
class POGO {
String property
void setProperty(String name, Object value) {
this.@"$name" = 'overridden'
}
}
def pogo = new POGO()
pogo.property = 'a'
assert pogo.property == 'overridden'1.1.3. get/setMetaClass
You can access an object’s metaClass or set your own MetaClass implementation for changing the default interception mechanism. For example, you can write your own implementation of the MetaClass interface and assign it to objects in order to change the interception mechanism:
// getMetaclass
someObject.metaClass
// setMetaClass
someObject.metaClass = new OwnMetaClassImplementation()| You can find an additional example in the GroovyInterceptable topic. |
1.2. get/setAttribute
This functionality is related to the MetaClass implementation. In the default implementation you can access fields without invoking their getters and setters. The examples below demonstrates this approach:
class SomeGroovyClass {
def field1 = 'ha'
def field2 = 'ho'
def getField1() {
return 'getHa'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.metaClass.getAttribute(someGroovyClass, 'field1') == 'ha'
assert someGroovyClass.metaClass.getAttribute(someGroovyClass, 'field2') == 'ho'class POGO {
private String field
String property1
void setProperty1(String property1) {
this.property1 = "setProperty1"
}
}
def pogo = new POGO()
pogo.metaClass.setAttribute(pogo, 'field', 'ha')
pogo.metaClass.setAttribute(pogo, 'property1', 'ho')
assert pogo.field == 'ha'
assert pogo.property1 == 'ho'1.3. methodMissing
Groovy supports the concept of methodMissing. This method differs from invokeMethod in that it
is only invoked in the case of a failed method dispatch when no method can be found for the given name and/or the
given arguments:
class Foo {
def methodMissing(String name, def args) {
return "this is me"
}
}
assert new Foo().someUnknownMethod(42l) == 'this is me'Typically when using methodMissing it is possible to cache the result for the next time the same method is called.
For example, consider dynamic finders in GORM. These are implemented in terms of methodMissing. The code resembles
something like this:
class GORM {
def dynamicMethods = [...] // an array of dynamic methods that use regex
def methodMissing(String name, args) {
def method = dynamicMethods.find { it.match(name) }
if(method) {
GORM.metaClass."$name" = { Object[] varArgs ->
method.invoke(delegate, name, varArgs)
}
return method.invoke(delegate,name, args)
}
else throw new MissingMethodException(name, delegate, args)
}
}Notice how, if we find a method to invoke, we then dynamically register a new method on the fly using ExpandoMetaClass.
This is so that the next time the same method is called it is more efficient. This way of using methodMissing does not have
the overhead of invokeMethod and is not expensive from the second call on.
1.4. propertyMissing
Groovy supports the concept of propertyMissing for intercepting otherwise failing property resolution attempts. In the
case of a getter method, propertyMissing takes a single String argument containing the property name:
class Foo {
def propertyMissing(String name) { name }
}
assert new Foo().boo == 'boo'The propertyMissing(String) method is only called when no getter method for the given property can be found by the Groovy
runtime.
For setter methods a second propertyMissing definition can be added that takes an additional value argument:
class Foo {
def storage = [:]
def propertyMissing(String name, value) { storage[name] = value }
def propertyMissing(String name) { storage[name] }
}
def f = new Foo()
f.foo = "bar"
assert f.foo == "bar"As with methodMissing it is best practice to dynamically register new properties at runtime to improve the overall lookup
performance.
1.5. static methodMissing
Static variant of methodMissing method can be added via the ExpandoMetaClass
or can be implemented at the class level with $static_methodMissing method.
class Foo {
static def $static_methodMissing(String name, Object args) {
return "Missing static method name is $name"
}
}
assert Foo.bar() == 'Missing static method name is bar'1.6. static propertyMissing
Static variant of propertyMissing method can be added via the ExpandoMetaClass
or can be implemented at the class level with $static_propertyMissing method.
class Foo {
static def $static_propertyMissing(String name) {
return "Missing static property name is $name"
}
}
assert Foo.foobar == 'Missing static property name is foobar'1.7. GroovyInterceptable
The groovy.lang.GroovyInterceptable interface is marker interface that extends GroovyObject and is used to notify the Groovy runtime that all methods should be intercepted through the method dispatcher mechanism of the Groovy runtime.
package groovy.lang;
public interface GroovyInterceptable extends GroovyObject {
}When a Groovy object implements the GroovyInterceptable interface, its invokeMethod() is called for any method calls. Below you can see a simple example of an object of this type:
class Interception implements GroovyInterceptable {
def definedMethod() { }
def invokeMethod(String name, Object args) {
'invokedMethod'
}
}The next piece of code is a test which shows that both calls to existing and non-existing methods will return the same value.
class InterceptableTest extends GroovyTestCase {
void testCheckInterception() {
def interception = new Interception()
assert interception.definedMethod() == 'invokedMethod'
assert interception.someMethod() == 'invokedMethod'
}
}
We cannot use default groovy methods like println because these methods are injected into all Groovy objects so they will be intercepted too.
|
If we want to intercept all method calls but do not want to implement the GroovyInterceptable interface we can implement invokeMethod() on an object’s MetaClass.
This approach works for both POGOs and POJOs, as shown by this example:
class InterceptionThroughMetaClassTest extends GroovyTestCase {
void testPOJOMetaClassInterception() {
String invoking = 'ha'
invoking.metaClass.invokeMethod = { String name, Object args ->
'invoked'
}
assert invoking.length() == 'invoked'
assert invoking.someMethod() == 'invoked'
}
void testPOGOMetaClassInterception() {
Entity entity = new Entity('Hello')
entity.metaClass.invokeMethod = { String name, Object args ->
'invoked'
}
assert entity.build(new Object()) == 'invoked'
assert entity.someMethod() == 'invoked'
}
}
Additional information about MetaClass can be found in the MetaClasses section.
|
1.8. Categories
There are situations where it is useful if a class not under control had additional methods. In order to enable this capability, Groovy implements a feature borrowed from Objective-C, called Categories.
Categories are implemented with so-called category classes. A category class is special in that it needs to meet certain pre-defined rules for defining extension methods.
There are a few categories that are included in the system for adding functionality to classes that make them more usable within the Groovy environment:
Category classes aren’t enabled by default. To use the methods defined in a category class it is necessary to apply
the scoped use method that is provided by the GDK and available from inside every Groovy object instance:
use(TimeCategory) {
println 1.minute.from.now (1)
println 10.hours.ago
def someDate = new Date() (2)
println someDate - 3.months
}| 1 | TimeCategory adds methods to Integer |
| 2 | TimeCategory adds methods to Date |
The use method takes the category class as its first parameter and a closure code block as second parameter. Inside the
Closure access to the category methods is available. As can be seen in the example above even JDK classes
like java.lang.Integer or java.util.Date can be enriched with user-defined methods.
A category needs not to be directly exposed to the user code, the following will also do:
class JPACategory{
// Let's enhance JPA EntityManager without getting into the JSR committee
static void persistAll(EntityManager em , Object[] entities) { //add an interface to save all
entities?.each { em.persist(it) }
}
}
def transactionContext = {
EntityManager em, Closure c ->
def tx = em.transaction
try {
tx.begin()
use(JPACategory) {
c()
}
tx.commit()
} catch (e) {
tx.rollback()
} finally {
//cleanup your resource here
}
}
// user code, they always forget to close resource in exception, some even forget to commit, let's not rely on them.
EntityManager em; //probably injected
transactionContext (em) {
em.persistAll(obj1, obj2, obj3)
// let's do some logics here to make the example sensible
em.persistAll(obj2, obj4, obj6)
}When we have a look at the groovy.time.TimeCategory class we see that the extension methods are all declared as static
methods. In fact, this is one of the requirements that must be met by category classes for its methods to be successfully added to
a class inside the use code block:
public class TimeCategory {
public static Date plus(final Date date, final BaseDuration duration) {
return duration.plus(date);
}
public static Date minus(final Date date, final BaseDuration duration) {
final Calendar cal = Calendar.getInstance();
cal.setTime(date);
cal.add(Calendar.YEAR, -duration.getYears());
cal.add(Calendar.MONTH, -duration.getMonths());
cal.add(Calendar.DAY_OF_YEAR, -duration.getDays());
cal.add(Calendar.HOUR_OF_DAY, -duration.getHours());
cal.add(Calendar.MINUTE, -duration.getMinutes());
cal.add(Calendar.SECOND, -duration.getSeconds());
cal.add(Calendar.MILLISECOND, -duration.getMillis());
return cal.getTime();
}
// ...Another requirement is the first argument of the static method must define the type the method is attached to once being activated. The other arguments are the normal arguments the method will take as parameters.
Because of the parameter and static method convention, category method definitions may be a bit less intuitive than
normal method definitions. As an alternative Groovy comes with a @Category annotation that transforms annotated classes
into category classes at compile-time.
class Distance {
def number
String toString() { "${number}m" }
}
@Category(Number)
class NumberCategory {
Distance getMeters() {
new Distance(number: this)
}
}
use (NumberCategory) {
assert 42.meters.toString() == '42m'
}Applying the @Category annotation has the advantage of being able to use instance methods without the target type as a
first parameter. The target type class is given as an argument to the annotation instead.
There is a distinct section on @Category in the compile-time metaprogramming section.
|
1.9. Metaclasses
As explained earlier, Metaclasses play a central role in method resolution.
For every method invocation from groovy code, Groovy will find the MetaClass for the given object
and delegate the method resolution to the metaclass via
groovy.lang.MetaClass#invokeMethod(java.lang.Class,java.lang.Object,java.lang.String,java.lang.Object,boolean,boolean)
which should not be confused with
groovy.lang.GroovyObject#invokeMethod(java.lang.String,java.lang.Object)
which happens to be a method that the metaclass may eventually call.
1.9.1. The default metaclass MetaClassImpl
By default, objects get an instance of MetaClassImpl that implements the default method lookup.
This method lookup includes looking up of the method in the object class ("regular" method) but also if no
method is found this way it will resort to calling methodMissing and ultimately
groovy.lang.GroovyObject#invokeMethod(java.lang.String,java.lang.Object)
class Foo {}
def f = new Foo()
assert f.metaClass =~ /MetaClassImpl/1.9.2. Custom metaclasses
You can change the metaclass of any object or class and replace it with a
custom implementation of the MetaClass groovy.lang.MetaClass.
Usually you will want to extend one of the existing metaclasses such as
MetaClassImpl, DelegatingMetaClass, ExpandoMetaClass, or ProxyMetaClass;
otherwise you will need to implement the complete method lookup logic.
Before using a new metaclass instance you should call
groovy.lang.MetaClass#initialize(),
otherwise the metaclass may or may not behave as expected.
Delegating metaclass
If you only need to decorate an existing metaclass the DelegatingMetaClass simplifies that use case.
The old metaclass implementation is still accessible via super making it easy to apply
pretransformations to the inputs, routing to other methods and postprocessing the outputs.
class Foo { def bar() { "bar" } }
class MyFooMetaClass extends DelegatingMetaClass {
MyFooMetaClass(MetaClass metaClass) { super(metaClass) }
MyFooMetaClass(Class theClass) { super(theClass) }
Object invokeMethod(Object object, String methodName, Object[] args) {
def result = super.invokeMethod(object,methodName.toLowerCase(), args)
result.toUpperCase();
}
}
def mc = new MyFooMetaClass(Foo.metaClass)
mc.initialize()
Foo.metaClass = mc
def f = new Foo()
assert f.BAR() == "BAR" // the new metaclass routes .BAR() to .bar() and uppercases the resultMagic package
It is possible to change the metaclass at startup time by giving the metaclass a specially crafted (magic) class name and package name. In order to change the metaclass for java.lang.Integer it’s enough to put a class groovy.runtime.metaclass.java.lang.IntegerMetaClass in the classpath. This is useful, for example, when working with frameworks if you want to do metaclass changes before your code is executed by the framework. The general form of the magic package is groovy.runtime.metaclass.[package].[class]MetaClass. In the example below the [package] is java.lang and the [class] is Integer:
// file: IntegerMetaClass.groovy
package groovy.runtime.metaclass.java.lang;
class IntegerMetaClass extends DelegatingMetaClass {
IntegerMetaClass(MetaClass metaClass) { super(metaClass) }
IntegerMetaClass(Class theClass) { super(theClass) }
Object invokeMethod(Object object, String name, Object[] args) {
if (name =~ /isBiggerThan/) {
def other = name.split(/isBiggerThan/)[1].toInteger()
object > other
} else {
return super.invokeMethod(object,name, args);
}
}
}By compiling the above file with groovyc IntegerMetaClass.groovy a ./groovy/runtime/metaclass/java/lang/IntegerMetaClass.class will be generated. The example below will use this new metaclass:
// File testInteger.groovy
def i = 10
assert i.isBiggerThan5()
assert !i.isBiggerThan15()
println i.isBiggerThan5()By running that file with groovy -cp . testInteger.groovy the IntegerMetaClass will be in the classpath and therefore it will become the metaclass for java.lang.Integer intercepting the method calls to isBiggerThan*() methods.
1.9.3. Per instance metaclass
You can change the metaclass of individual objects separately, so it’s possible to have multiple object of the same class with different metaclasses.
class Foo { def bar() { "bar" }}
class FooMetaClass extends DelegatingMetaClass {
FooMetaClass(MetaClass metaClass) { super(metaClass) }
Object invokeMethod(Object object, String name, Object[] args) {
super.invokeMethod(object,name,args).toUpperCase()
}
}
def f1 = new Foo()
def f2 = new Foo()
f2.metaClass = new FooMetaClass(f2.metaClass)
assert f1.bar() == "bar"
assert f2.bar() == "BAR"
assert f1.metaClass =~ /MetaClassImpl/
assert f2.metaClass =~ /FooMetaClass/
assert f1.class.toString() == "class Foo"
assert f2.class.toString() == "class Foo"1.9.4. ExpandoMetaClass
Groovy comes with a special MetaClass the so-called ExpandoMetaClass. It is special in that it allows for dynamically
adding or changing methods, constructors, properties and even static methods by using a neat closure syntax.
Applying those modifications can be especially useful in mocking or stubbing scenarios as shown in the Testing Guide.
Every java.lang.Class is supplied by Groovy with a special metaClass property that will give you a reference to an
ExpandoMetaClass instance. This instance can then be used to add methods or change the behaviour of already existing
ones.
By default ExpandoMetaClass doesn’t do inheritance. To enable this you must call ExpandoMetaClass#enableGlobally()
before your app starts such as in the main method or servlet bootstrap.
|
The following sections go into detail on how ExpandoMetaClass can be used in various scenarios.
Methods
Once the ExpandoMetaClass is accessed by calling the metaClass property, methods can be added by using either the left shift
<< or the = operator.
Note that the left shift operator is used to append a new method. If a public method with the same name and
parameter types is declared by the class or interface, including those inherited from superclasses and superinterfaces
but excluding those added to the metaClass at runtime, an exception will be thrown. If you want to replace a
method declared by the class or interface you can use the = operator.
|
The operators are applied on a non-existent property of metaClass passing an instance of a Closure code block.
class Book {
String title
}
Book.metaClass.titleInUpperCase << {-> title.toUpperCase() }
def b = new Book(title:"The Stand")
assert "THE STAND" == b.titleInUpperCase()The example above shows how a new method can be added to a class by accessing the metaClass property and using the << or
= operator to assign a Closure code block. The Closure parameters are interpreted as method parameters. Parameterless methods
can be added by using the {→ …} syntax.
Properties
ExpandoMetaClass supports two mechanisms for adding or overriding properties.
Firstly, it has support for declaring a mutable property by simply assigning a value to a property of metaClass:
class Book {
String title
}
Book.metaClass.author = "Stephen King"
def b = new Book()
assert "Stephen King" == b.authorAnother way is to add getter and/or setter methods by using the standard mechanisms for adding instance methods.
class Book {
String title
}
Book.metaClass.getAuthor << {-> "Stephen King" }
def b = new Book()
assert "Stephen King" == b.authorIn the source code example above the property is dictated by the closure and is a read-only property. It is feasible to add an equivalent setter method but then the property value needs to be stored for later usage. This could be done as shown in the following example.
class Book {
String title
}
def properties = Collections.synchronizedMap([:])
Book.metaClass.setAuthor = { String value ->
properties[System.identityHashCode(delegate) + "author"] = value
}
Book.metaClass.getAuthor = {->
properties[System.identityHashCode(delegate) + "author"]
}This is not the only technique however. For example in a servlet container one way might be to store the values in the currently executing request as request attributes (as is done in some cases in Grails).
Constructors
Constructors can be added by using a special constructor property. Either the << or = operator can be used
to assign a Closure code block. The Closure arguments will become the constructor arguments when the code is
executed at runtime.
class Book {
String title
}
Book.metaClass.constructor << { String title -> new Book(title:title) }
def book = new Book('Groovy in Action - 2nd Edition')
assert book.title == 'Groovy in Action - 2nd Edition'| Be careful when adding constructors however, as it is very easy to get into stack overflow troubles. |
Static Methods
Static methods can be added using the same technique as instance methods with the addition of the static qualifier
before the method name.
class Book {
String title
}
Book.metaClass.static.create << { String title -> new Book(title:title) }
def b = Book.create("The Stand")Borrowing Methods
With ExpandoMetaClass it is possible to use Groovy’s method pointer syntax to borrow methods from other classes.
class Person {
String name
}
class MortgageLender {
def borrowMoney() {
"buy house"
}
}
def lender = new MortgageLender()
Person.metaClass.buyHouse = lender.&borrowMoney
def p = new Person()
assert "buy house" == p.buyHouse()Dynamic Method Names
Since Groovy allows you to use Strings as property names this in turns allows you to dynamically create method and property names at runtime. To create a method with a dynamic name simply use the language feature of reference property names as strings.
class Person {
String name = "Fred"
}
def methodName = "Bob"
Person.metaClass."changeNameTo${methodName}" = {-> delegate.name = "Bob" }
def p = new Person()
assert "Fred" == p.name
p.changeNameToBob()
assert "Bob" == p.nameThe same concept can be applied to static methods and properties.
One application of dynamic method names can be found in the Grails web application framework. The concept of "dynamic codecs" is implemented by using dynamic method names.
HTMLCodec Classclass HTMLCodec {
static encode = { theTarget ->
HtmlUtils.htmlEscape(theTarget.toString())
}
static decode = { theTarget ->
HtmlUtils.htmlUnescape(theTarget.toString())
}
}The example above shows a codec implementation. Grails comes with various codec implementations each defined in a single class.
At runtime there will be multiple codec classes in the application classpath. At application startup the framework adds
a encodeXXX and a decodeXXX method to certain metaclasses where XXX is the first part of the codec class name (e.g.
encodeHTML). This mechanism is in the following shown in some Groovy pseudocode:
def codecs = classes.findAll { it.name.endsWith('Codec') }
codecs.each { codec ->
Object.metaClass."encodeAs${codec.name-'Codec'}" = { codec.newInstance().encode(delegate) }
Object.metaClass."decodeFrom${codec.name-'Codec'}" = { codec.newInstance().decode(delegate) }
}
def html = '<html><body>hello</body></html>'
assert '<html><body>hello</body></html>' == html.encodeAsHTML()Runtime Discovery
At runtime it is often useful to know what other methods or properties exist at the time the method is executed. ExpandoMetaClass
provides the following methods as of this writing:
-
getMetaMethod -
hasMetaMethod -
getMetaProperty -
hasMetaProperty
Why can’t you just use reflection? Well because Groovy is different, it has the methods that are "real" methods and methods that are available only at runtime. These are sometimes (but not always) represented as MetaMethods. The MetaMethods tell you what methods are available at runtime, thus your code can adapt.
This is of particular use when overriding invokeMethod, getProperty and/or setProperty.
GroovyObject Methods
Another feature of ExpandoMetaClass is that it allows to override the methods invokeMethod, getProperty and
setProperty, all of them can be found in the groovy.lang.GroovyObject class.
The following example shows how to override invokeMethod:
class Stuff {
def invokeMe() { "foo" }
}
Stuff.metaClass.invokeMethod = { String name, args ->
def metaMethod = Stuff.metaClass.getMetaMethod(name, args)
def result
if(metaMethod) result = metaMethod.invoke(delegate,args)
else {
result = "bar"
}
result
}
def stf = new Stuff()
assert "foo" == stf.invokeMe()
assert "bar" == stf.doStuff()The first step in the Closure code is to look up the MetaMethod for the given name and arguments. If the method
can be found everything is fine and it is delegated to. If not, a dummy value is returned.
A MetaMethod is a method that is known to exist on the MetaClass whether added at runtime or at compile-time.
|
The same logic can be used to override setProperty or getProperty.
class Person {
String name = "Fred"
}
Person.metaClass.getProperty = { String name ->
def metaProperty = Person.metaClass.getMetaProperty(name)
def result
if(metaProperty) result = metaProperty.getProperty(delegate)
else {
result = "Flintstone"
}
result
}
def p = new Person()
assert "Fred" == p.name
assert "Flintstone" == p.otherThe important thing to note here is that instead of a MetaMethod a MetaProperty instance is looked up. If that exists
the getProperty method of the MetaProperty is called, passing the delegate.
Overriding Static invokeMethod
ExpandoMetaClass even allows for overriding static method with a special invokeMethod syntax.
class Stuff {
static invokeMe() { "foo" }
}
Stuff.metaClass.'static'.invokeMethod = { String name, args ->
def metaMethod = Stuff.metaClass.getStaticMetaMethod(name, args)
def result
if(metaMethod) result = metaMethod.invoke(delegate,args)
else {
result = "bar"
}
result
}
assert "foo" == Stuff.invokeMe()
assert "bar" == Stuff.doStuff()The logic that is used for overriding the static method is the same as we’ve seen before for overriding instance methods. The
only difference is the access to the metaClass.static property and the call to getStaticMethodName for retrieving
the static MetaMethod instance.
Extending Interfaces
It is possible to add methods onto interfaces with ExpandoMetaClass. To do this however, it must be enabled
globally using the ExpandoMetaClass.enableGlobally() method before application start-up.
List.metaClass.sizeDoubled = {-> delegate.size() * 2 }
def list = []
list << 1
list << 2
assert 4 == list.sizeDoubled()1.10. Extension modules
1.10.1. Extending existing classes
An extension module allows you to add new methods to existing classes, including classes which are precompiled, like classes from the JDK. Those new methods, unlike those defined through a metaclass or using a category, are available globally. For example, when you write:
def file = new File(...)
def contents = file.getText('utf-8')The getText method doesn’t exist on the File class. However, Groovy knows it because it is defined in a special
class, ResourceGroovyMethods:
public static String getText(File file, String charset) throws IOException {
return IOGroovyMethods.getText(newReader(file, charset));
}You may notice that the extension method is defined using a static method in a helper class (where various extension
methods are defined). The first argument of the getText method corresponds to the receiver, while additional parameters
correspond to the arguments of the extension method. So here, we are defining a method called getText on
the File class (because the first argument is of type File), which takes a single argument as a parameter (the encoding String).
The process of creating an extension module is simple:
-
write an extension class like above
-
write a module descriptor file
Then you have to make the extension module visible to Groovy, which is as simple as having the extension module classes and descriptor available on classpath. This means that you have the choice:
-
either provide the classes and module descriptor directly on classpath
-
or bundle your extension module into a jar for reusability
An extension module may add two kind of methods to a class:
-
instance methods (to be called on an instance of a class)
-
static methods (to be called on the class itself)
1.10.2. Instance methods
To add an instance method to an existing class, you need to create an extension class. For example, let’s say you
want to add a maxRetries method on Integer which accepts a closure and executes it at most n times until no
exception is thrown. To do that, you only need to write the following:
class MaxRetriesExtension { (1)
static void maxRetries(Integer self, Closure code) { (2)
assert self >= 0
int retries = self
Throwable e = null
while (retries > 0) {
try {
code.call()
break
} catch (Throwable err) {
e = err
retries--
}
}
if (retries == 0 && e) {
throw e
}
}
}| 1 | The extension class |
| 2 | First argument of the static method corresponds to the receiver of the message, that is to say the extended instance |
Then, after having declared your extension class, you can call it this way:
int i=0
5.maxRetries {
i++
}
assert i == 1
i=0
try {
5.maxRetries {
i++
throw new RuntimeException("oops")
}
} catch (RuntimeException e) {
assert i == 5
}1.10.3. Static methods
It is also possible to add static methods to a class. In that case, the static method needs to be defined in its own file. Static and instance extension methods cannot be present in the same class.
class StaticStringExtension { (1)
static String greeting(String self) { (2)
'Hello, world!'
}
}| 1 | The static extension class |
| 2 | First argument of the static method corresponds to the class being extended and is unused |
In which case you can call it directly on the String class:
assert String.greeting() == 'Hello, world!'1.10.4. Module descriptor
For Groovy to be able to load your extension methods, you must declare
your extension helper classes. You must create a file named
org.codehaus.groovy.runtime.ExtensionModule into the
META-INF/groovy directory:
moduleName=Test module for specifications moduleVersion=1.0-test extensionClasses=support.MaxRetriesExtension staticExtensionClasses=support.StaticStringExtension
The module descriptor requires 4 keys:
-
moduleName : the name of your module
-
moduleVersion: the version of your module. Note that version number is only used to check that you don’t load the same module in two different versions.
-
extensionClasses: the list of extension helper classes for instance methods. You can provide several classes, given that they are comma separated.
-
staticExtensionClasses: the list of extension helper classes for static methods. You can provide several classes, given that they are comma separated.
Note that it is not required for a module to define both static helpers and instance helpers, and that you may add several classes to a single module. You can also extend different classes in a single module without problem. It is even possible to use different classes in a single extension class, but it is recommended to group extension methods into classes by feature set.
1.10.5. Extension modules and classpath
It’s worth noting that you can’t use an extension which is compiled at the same time as code using it. That means that to use an extension, it has to be available on classpath, as compiled classes, before the code using it gets compiled. Usually, this means that you can’t have the test classes in the same source unit as the extension class itself. Since in general, test sources are separated from normal sources and executed in another step of the build, this is not an issue.
1.10.6. Compatibility with type checking
Unlike categories, extension modules are compatible with type checking: if they are found on classpath, then the type checker is aware of the extension methods and will not complain when you call them. It is also compatible with static compilation.
2. Compile-time metaprogramming
Compile-time metaprogramming in Groovy allows code generation at compile-time. Those transformations are altering the Abstract Syntax Tree (AST) of a program, which is why in Groovy we call it AST transformations. AST transformations allow you to hook into the compilation process, modify the AST and continue the compilation process to generate regular bytecode. Compared to runtime metaprogramming, this has the advantage of making the changes visible in the class file itself (that is to say, in the bytecode). Making it visible in the bytecode is important for example if you want the transformations to be part of the class contract (implementing interfaces, extending abstract classes, …) or even if you need your class to be callable from Java (or other JVM languages). For example, an AST transformation can add methods to a class. If you do it with runtime metaprogramming, the new method would only be visible from Groovy. If you do the same using compile-time metaprogramming, the method would be visible from Java too. Last but not least, performance would likely be better with compile-time metaprogramming (because no initialization phase is required).
In this section, we will start with explaining the various compile-time transformations that are bundled with the Groovy distribution. In a subsequent section, we will describe how you can implement your own AST transformations and what are the disadvantages of this technique.
2.1. Available AST transformations
Groovy comes with various AST transformations covering different needs: reducing boilerplate (code generation), implementing design patterns (delegation, …), logging, declarative concurrency, cloning, safer scripting, tweaking the compilation, implementing Swing patterns, testing and eventually managing dependencies. If none of those AST transformations cover your needs, you can still implement your own, as show in section Developing your own AST transformations.
AST transformations can be separated into two categories:
-
global AST transformations are applied transparently, globally, as soon as they are found on compile classpath
-
local AST transformations are applied by annotating the source code with markers. Unlike global AST transformations, local AST transformations may support parameters.
Groovy doesn’t ship with any global AST transformation, but you can find a list of local AST transformations available for you to use in your code here:
2.1.1. Code generation transformations
This category of transformation includes AST transformations which help removing boilerplate code. This is typically code that you have to write but that does not carry any useful information. By autogenerating this boilerplate code, the code you have to write is left clean and concise and the chance of introducing an error by getting such boilerplate code incorrect is reduced.
@groovy.transform.ToString
The @ToString AST transformation generates a human-readable toString representation of the class. For example,
annotating the Person class like below will automatically generate the toString method for you:
import groovy.transform.ToString
@ToString
class Person {
String firstName
String lastName
}With this definition, then the following assertion passes, meaning that a toString method taking the field values from
the class and printing them out has been generated:
def p = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p.toString() == 'Person(Jack, Nicholson)'The @ToString annotation accepts several parameters which are summarized in the following table:
| Attribute | Default value | Description | Example |
|---|---|---|---|
excludes |
Empty list |
List of properties to exclude from toString |
|
includes |
Undefined marker list (indicates all fields) |
List of fields to include in toString |
|
includeSuper |
False |
Should superclass be included in toString |
|
includeNames |
false |
Whether to include names of properties in generated toString. |
|
includeFields |
False |
Should fields be included in toString, in addition to properties |
|
includeSuperProperties |
False |
Should super properties be included in toString |
|
includeSuperFields |
False |
Should visible super fields be included in toString |
|
ignoreNulls |
False |
Should properties/fields with null value be displayed |
|
includePackage |
True |
Use fully qualified class name instead of simple name in toString |
|
allProperties |
True |
Include all JavaBean properties in toString |
|
cache |
False |
Cache the toString string. Should only be set to true if the class is immutable. |
|
allNames |
False |
Should fields and/or properties with internal names be included in the generated toString |
|
@groovy.transform.EqualsAndHashCode
The @EqualsAndHashCode AST transformation aims at generating equals and hashCode methods for you. The generated
hashcode follows the best practices as described in Effective Java by Josh Bloch:
import groovy.transform.EqualsAndHashCode
@EqualsAndHashCode
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1==p2
assert p1.hashCode() == p2.hashCode()There are several options available to tweak the behavior of @EqualsAndHashCode:
| Attribute | Default value | Description | Example |
|---|---|---|---|
excludes |
Empty list |
List of properties to exclude from equals/hashCode |
|
includes |
Undefined marker list (indicating all fields) |
List of fields to include in equals/hashCode |
|
cache |
False |
Cache the hashCode computation. Should only be set to true if the class is immutable. |
|
callSuper |
False |
Whether to include super in equals and hashCode calculations |
|
includeFields |
False |
Should fields be included in equals/hashCode, in addition to properties |
|
useCanEqual |
True |
Should equals call canEqual helper method. |
|
allProperties |
False |
Should JavaBean properties be included in equals and hashCode calculations |
|
allNames |
False |
Should fields and/or properties with internal names be included in equals and hashCode calculations |
|
@groovy.transform.TupleConstructor
The @TupleConstructor annotation aims at eliminating boilerplate code by generating constructors for you. A tuple
constructor is created having a parameter for each property (and possibly each field). Each parameter has a default value
(using the initial value of the property if present or otherwise Java’s default value according to the properties type).
Implementation Details
Normally you don’t need to understand the implementation details of the generated constructor(s); you just use them in the normal way. However, if you want to add multiple constructors, understand Java integration options or meet requirements of some dependency injection frameworks, then some details are useful.
As previously mentioned, the generated constructor has default values applied. In later compilation phases, the Groovy compiler’s standard default value processing behavior is then applied. The end result is that multiple constructors are placed within the bytecode of your class. This provides a well understood semantics and is also useful for Java integration purposes. As an example, the following code will generate 3 constructors:
import groovy.transform.TupleConstructor
@TupleConstructor
class Person {
String firstName
String lastName
}
// traditional map-style constructor
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
// generated tuple constructor
def p2 = new Person('Jack', 'Nicholson')
// generated tuple constructor with default value for second property
def p3 = new Person('Jack')The first constructor is a no-arg constructor which allows the traditional map-style construction so long as you don’t have final properties. Groovy calls the no-arg constructor and then the relevant setters under the covers. It is worth noting that if the first property (or field) has type LinkedHashMap or if there is a single Map, AbstractMap or HashMap property (or field), then the map-style named arguments won’t be available.
The other constructors are generated by taking the properties in the order they are defined. Groovy will generate as many constructors as there are properties (or fields, depending on the options).
Setting the defaults attribute (see the available configuration options table) to false, disables the normal default values behavior which means:
-
Exactly one constructor will be produced
-
Attempting to use an initial value will produce an error
-
Map-style named arguments won’t be available
This attribute is normally only used in situations where another Java framework is expecting exactly one constructor, e.g. injection frameworks or JUnit parameterized runners.
Immutability support
If the @PropertyOptions annotation is also found on the class with the @TupleConstructor annotation,
then the generated constructor may contain custom property handling logic.
The propertyHandler attribute on the @PropertyOptions annotation could for instance be set to
ImmutablePropertyHandler which will result in the addition of the necessary logic for immutable classes
(defensive copy in, cloning, etc.). This normally would happen automatically behind the scenes when you use
the @Immutable meta-annotation.
Some of the annotation attributes might not be supported by all property handlers.
Customization options
The @TupleConstructor AST transformation accepts several annotation attributes:
| Attribute | Default value | Description | Example |
|---|---|---|---|
excludes |
Empty list |
List of properties to exclude from tuple constructor generation |
|
includes |
Undefined list (indicates all fields) |
List of fields to include in tuple constructor generation |
|
includeProperties |
True |
Should properties be included in tuple constructor generation |
|
includeFields |
False |
Should fields be included in tuple constructor generation, in addition to properties |
|
includeSuperProperties |
True |
Should properties from super classes be included in tuple constructor generation |
|
includeSuperFields |
False |
Should fields from super classes be included in tuple constructor generation |
|
callSuper |
False |
Should super properties be called within a call to the parent constructor rather than set as properties |
|
force |
False |
By default, the transformation will do nothing if a constructor is already defined. Setting this attribute to true, the constructor will be generated and it’s your responsibility to ensure that no duplicate constructor is defined. |
|
defaults |
True |
Indicates that default value processing is enabled for constructor parameters. Set to false to obtain exactly one constructor but with initial value support and named-arguments disabled. |
|
useSetters |
False |
By default, the transformation will directly set the backing field of each property from its corresponding constructor parameter. Setting this attribute to true, the constructor will instead call setters if they exist. It’s usually deemed bad style from within a constructor to call setters that can be overridden. It’s your responsibility to avoid such bad style. |
|
allNames |
False |
Should fields and/or properties with internal names be included within the constructor |
|
allProperties |
False |
Should JavaBean properties be included within the constructor |
|
pre |
empty |
A closure containing statements to be inserted at the start of the generated constructor(s) |
|
post |
empty |
A closure containing statements to be inserted at the end of the generated constructor(s) |
|
Setting the defaults annotation attribute to false and the force annotation attribute to true allows
multiple tuple constructors to be created by using different customization options for the different cases
(provided each case has a different type signature) as shown in the following example:
class Named {
String name
}
@ToString(includeSuperProperties=true, ignoreNulls=true, includeNames=true, includeFields=true)
@TupleConstructor(force=true, defaults=false)
@TupleConstructor(force=true, defaults=false, includeFields=true)
@TupleConstructor(force=true, defaults=false, includeSuperProperties=true)
class Book extends Named {
Integer published
private Boolean fiction
Book() {}
}
assert new Book("Regina", 2015).toString() == 'Book(published:2015, name:Regina)'
assert new Book(2015, false).toString() == 'Book(published:2015, fiction:false)'
assert new Book(2015).toString() == 'Book(published:2015)'
assert new Book().toString() == 'Book()'
assert Book.constructors.size() == 4Similarly, here is another example using different options for includes:
@ToString(includeSuperProperties=true, ignoreNulls=true, includeNames=true, includeFields=true)
@TupleConstructor(force=true, defaults=false, includes='name,year')
@TupleConstructor(force=true, defaults=false, includes='year,fiction')
@TupleConstructor(force=true, defaults=false, includes='name,fiction')
class Book {
String name
Integer year
Boolean fiction
}
assert new Book("Regina", 2015).toString() == 'Book(name:Regina, year:2015)'
assert new Book(2015, false).toString() == 'Book(year:2015, fiction:false)'
assert new Book("Regina", false).toString() == 'Book(name:Regina, fiction:false)'
assert Book.constructors.size() == 3@groovy.transform.MapConstructor
The @MapConstructor annotation aims at eliminating boilerplate code by generating a map constructor for you. A map
constructor is created such that each property in the class is set based on the value in the supplied map
having the key with the name of the property. Usage is as shown in this example:
import groovy.transform.*
@ToString
@MapConstructor
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1.toString() == 'Person(Jack, Nicholson)'The generated constructor will be roughly like this:
public Person(Map args) {
if (args.containsKey('firstName')) {
this.firstName = args.get('firstName')
}
if (args.containsKey('lastName')) {
this.lastName = args.get('lastName')
}
}@groovy.transform.Canonical
The @Canonical meta-annotation combines the @ToString,
@EqualsAndHashCode and @TupleConstructor
annotations:
import groovy.transform.Canonical
@Canonical
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1.toString() == 'Person(Jack, Nicholson)' // Effect of @ToString
def p2 = new Person('Jack','Nicholson') // Effect of @TupleConstructor
assert p2.toString() == 'Person(Jack, Nicholson)'
assert p1==p2 // Effect of @EqualsAndHashCode
assert p1.hashCode()==p2.hashCode() // Effect of @EqualsAndHashCodeA similar immutable class can be generated using the @Immutable meta-annotation instead.
The @Canonical meta-annotation supports the configuration options found in the annotations
it aggregates. See those annotations for more details.
import groovy.transform.Canonical
@Canonical(excludes=['lastName'])
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1.toString() == 'Person(Jack)' // Effect of @ToString(excludes=['lastName'])
def p2 = new Person('Jack') // Effect of @TupleConstructor(excludes=['lastName'])
assert p2.toString() == 'Person(Jack)'
assert p1==p2 // Effect of @EqualsAndHashCode(excludes=['lastName'])
assert p1.hashCode()==p2.hashCode() // Effect of @EqualsAndHashCode(excludes=['lastName'])The @Canonical meta-annotation can be used in conjunction with an explicit use one or more of its
component annotations, like this:
import groovy.transform.Canonical
@Canonical(excludes=['lastName'])
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1.toString() == 'Person(Jack)' // Effect of @ToString(excludes=['lastName'])
def p2 = new Person('Jack') // Effect of @TupleConstructor(excludes=['lastName'])
assert p2.toString() == 'Person(Jack)'
assert p1==p2 // Effect of @EqualsAndHashCode(excludes=['lastName'])
assert p1.hashCode()==p2.hashCode() // Effect of @EqualsAndHashCode(excludes=['lastName'])Any applicable annotation attributes from @Canonical are passed along to the explicit annotation but
attributes already existing in the explicit annotation take precedence.
@groovy.transform.InheritConstructors
The @InheritConstructor AST transformation aims at generating constructors matching super constructors for you. This
is in particular useful when overriding exception classes:
import groovy.transform.InheritConstructors
@InheritConstructors
class CustomException extends Exception {}
// all those are generated constructors
new CustomException()
new CustomException("A custom message")
new CustomException("A custom message", new RuntimeException())
new CustomException(new RuntimeException())
// Java 7 only
// new CustomException("A custom message", new RuntimeException(), false, true)The @InheritConstructor AST transformation supports the following configuration options:
| Attribute | Default value | Description | Example |
|---|---|---|---|
constructorAnnotations |
False |
Whether to carry over annotations from the constructor during copying |
|
parameterAnnotations |
False |
Whether to carry over annotations from the constructor parameters when copying the constructor |
|
@groovy.lang.Category
The @Category AST transformation simplifies the creation of Groovy categories. Historically, a Groovy category was
written like this:
class TripleCategory {
public static Integer triple(Integer self) {
3*self
}
}
use (TripleCategory) {
assert 9 == 3.triple()
}The @Category transformation lets you write the same using an instance-style class, rather than a static class style.
This removes the need for having the first argument of each method being the receiver. The category can be written like
this:
@Category(Integer)
class TripleCategory {
public Integer triple() { 3*this }
}
use (TripleCategory) {
assert 9 == 3.triple()
}Note that the mixed in class can be referenced using this instead. It’s also worth noting that using instance fields
in a category class is inherently unsafe: categories are not stateful (like traits).
@groovy.transform.IndexedProperty
The @IndexedProperty annotation aims at generating indexed getters/setters for properties of list/array types.
This is in particular useful if you want to use a Groovy class from Java. While Groovy supports GPath to access properties,
this is not available from Java. The @IndexedProperty annotation will generate indexed properties of the following
form:
class SomeBean {
@IndexedProperty String[] someArray = new String[2]
@IndexedProperty List someList = []
}
def bean = new SomeBean()
bean.setSomeArray(0, 'value')
bean.setSomeList(0, 123)
assert bean.someArray[0] == 'value'
assert bean.someList == [123]@groovy.lang.Lazy
The @Lazy AST transformation implements lazy initialization of fields. For example, the following code:
class SomeBean {
@Lazy LinkedList myField
}will produce the following code:
List $myField
List getMyField() {
if ($myField!=null) { return $myField }
else {
$myField = new LinkedList()
return $myField
}
}The default value which is used to initialize the field is the default constructor of the declaration type. It is possible to define a default value by using a closure on the right hand side of the property assignment, as in the following example:
class SomeBean {
@Lazy LinkedList myField = { ['a','b','c']}()
}
In that case, the generated code looks like the following:
List $myField
List getMyField() {
if ($myField!=null) { return $myField }
else {
$myField = { ['a','b','c']}()
return $myField
}
}
If the field is declared volatile then initialization will be synchronized using the double-checked locking pattern.
Using the soft=true parameter, the helper field will use a SoftReference instead, providing a simple way to
implement caching. In that case, if the garbage collector decides to collect the reference, initialization will occur
the next time the field is accessed.
@groovy.lang.Newify
The @Newify AST transformation is used to bring alternative syntaxes to construct objects:
-
Using the
Pythonstyle:
@Newify([Tree,Leaf])
class TreeBuilder {
Tree tree = Tree(Leaf('A'),Leaf('B'),Tree(Leaf('C')))
}
-
or using the
Rubystyle:
@Newify([Tree,Leaf])
class TreeBuilder {
Tree tree = Tree.new(Leaf.new('A'),Leaf.new('B'),Tree.new(Leaf.new('C')))
}
The Ruby version can be disabled by setting the auto flag to false.
@groovy.transform.Sortable
The @Sortable AST transformation is used to help write classes that are Comparable and easily sorted
typically by numerous properties. It is easy to use as shown in the following example where we annotate
the Person class:
import groovy.transform.Sortable
@Sortable class Person {
String first
String last
Integer born
}The generated class has the following properties:
-
it implements the
Comparableinterface -
it contains a
compareTomethod with an implementation based on the natural ordering of thefirst,lastandbornproperties -
it has three methods returning comparators:
comparatorByFirst,comparatorByLastandcomparatorByBorn.
The generated compareTo method will look like this:
public int compareTo(java.lang.Object obj) {
if (this.is(obj)) {
return 0
}
if (!(obj instanceof Person)) {
return -1
}
java.lang.Integer value = this.first <=> obj.first
if (value != 0) {
return value
}
value = this.last <=> obj.last
if (value != 0) {
return value
}
value = this.born <=> obj.born
if (value != 0) {
return value
}
return 0
}As an example of the generated comparators, the comparatorByFirst comparator will have a compare method that looks like this:
public int compare(java.lang.Object arg0, java.lang.Object arg1) {
if (arg0 == arg1) {
return 0
}
if (arg0 != null && arg1 == null) {
return -1
}
if (arg0 == null && arg1 != null) {
return 1
}
return arg0.first <=> arg1.first
}The Person class can be used wherever a Comparable is expected and the generated comparators
wherever a Comparator is expected as shown by these examples:
def people = [
new Person(first: 'Johnny', last: 'Depp', born: 1963),
new Person(first: 'Keira', last: 'Knightley', born: 1985),
new Person(first: 'Geoffrey', last: 'Rush', born: 1951),
new Person(first: 'Orlando', last: 'Bloom', born: 1977)
]
assert people[0] > people[2]
assert people.sort()*.last == ['Rush', 'Depp', 'Knightley', 'Bloom']
assert people.sort(false, Person.comparatorByFirst())*.first == ['Geoffrey', 'Johnny', 'Keira', 'Orlando']
assert people.sort(false, Person.comparatorByLast())*.last == ['Bloom', 'Depp', 'Knightley', 'Rush']
assert people.sort(false, Person.comparatorByBorn())*.last == ['Rush', 'Depp', 'Bloom', 'Knightley']Normally, all properties are used in the generated compareTo method in the priority order in which they are defined.
You can include or exclude certain properties from the generated compareTo method by giving a list of property names
in the includes or excludes annotation attributes. If using includes, the order of the property names given will
determine the priority of properties when comparing. To illustrate, consider the following Person class definition:
@Sortable(includes='first,born') class Person {
String last
int born
String first
}It will have two comparator methods comparatorByFirst and comparatorByBorn and the generated compareTo method will look like this:
public int compareTo(java.lang.Object obj) {
if (this.is(obj)) {
return 0
}
if (!(obj instanceof Person)) {
return -1
}
java.lang.Integer value = this.first <=> obj.first
if (value != 0) {
return value
}
value = this.born <=> obj.born
if (value != 0) {
return value
}
return 0
}This Person class can be used as follows:
def people = [
new Person(first: 'Ben', last: 'Affleck', born: 1972),
new Person(first: 'Ben', last: 'Stiller', born: 1965)
]
assert people.sort()*.last == ['Stiller', 'Affleck']The behavior of the @Sortable AST transformation can be further changed using the following additional parameters:
| Attribute | Default value | Description | Example |
|---|---|---|---|
allProperties |
True |
Should JavaBean properties (ordered after native properties) be used |
|
allNames |
False |
Should properties with "internal" names be used |
|
includeSuperProperties |
False |
Should super properties also be used (ordered first) |
|
@groovy.transform.builder.Builder
The @Builder AST transformation is used to help write classes that can be created using fluent api calls.
The transform supports multiple building strategies to cover a range of cases and there are a number
of configuration options to customize the building process. If you’re an AST hacker, you can also define your own
strategy class. The following table lists the available strategies that are bundled with Groovy and the
configuration options each strategy supports.
Strategy |
Description |
builderClassName |
builderMethodName |
buildMethodName |
prefix |
includes/excludes |
includeSuperProperties |
allNames |
|
chained setters |
n/a |
n/a |
n/a |
yes, default "set" |
yes |
n/a |
yes, default |
|
explicit builder class, class being built untouched |
n/a |
n/a |
yes, default "build" |
yes, default "" |
yes |
yes, default |
yes, default |
|
creates a nested helper class |
yes, default <TypeName>Builder |
yes, default "builder" |
yes, default "build" |
yes, default "" |
yes |
yes, default |
yes, default |
|
creates a nested helper class providing type-safe fluent creation |
yes, default <TypeName>Initializer |
yes, default "createInitializer" |
yes, default "create" but usually only used internally |
yes, default "" |
yes |
yes, default |
yes, default |
To use the SimpleStrategy, annotate your Groovy class using the @Builder annotation, and specify the strategy as shown in this example:
import groovy.transform.builder.*
@Builder(builderStrategy=SimpleStrategy)
class Person {
String first
String last
Integer born
}Then, just call the setters in a chained fashion as shown here:
def p1 = new Person().setFirst('Johnny').setLast('Depp').setBorn(1963)
assert "$p1.first $p1.last" == 'Johnny Depp'For each property, a generated setter will be created which looks like this:
public Person setFirst(java.lang.String first) {
this.first = first
return this
}You can specify a prefix as shown in this example:
import groovy.transform.builder.*
@Builder(builderStrategy=SimpleStrategy, prefix="")
class Person {
String first
String last
Integer born
}And calling the chained setters would look like this:
def p = new Person().first('Johnny').last('Depp').born(1963)
assert "$p.first $p.last" == 'Johnny Depp'You can use the SimpleStrategy in conjunction with @TupleConstructor. If your @Builder
annotation doesn’t have explicit includes or excludes annotation attributes but your @TupleConstructor
annotation does, the ones from @TupleConstructor will be re-used for @Builder. The same applies for any
annotation aliases which combine @TupleConstructor such as @Canonical.
The annotation attribute useSetters can be used if you have a setter which you want called as part of the
construction process. See the JavaDoc for details.
The annotation attributes builderClassName, buildMethodName, builderMethodName, forClass and includeSuperProperties are not supported for this strategy.
Groovy already has built-in building mechanisms. Don’t rush to using @Builder if the built-in mechanisms meet your needs. Some examples:
|
def p2 = new Person(first: 'Keira', last: 'Knightley', born: 1985)
def p3 = new Person().with {
first = 'Geoffrey'
last = 'Rush'
born = 1951
}To use the ExternalStrategy, create and annotate a Groovy builder class using the @Builder annotation, specify the
class the builder is for using forClass and indicate use of the ExternalStrategy.
Suppose you have the following class you would like a builder for:
class Person {
String first
String last
int born
}you explicitly create and use your builder class as follows:
import groovy.transform.builder.*
@Builder(builderStrategy=ExternalStrategy, forClass=Person)
class PersonBuilder { }
def p = new PersonBuilder().first('Johnny').last('Depp').born(1963).build()
assert "$p.first $p.last" == 'Johnny Depp'Note that the (normally empty) builder class you provide will be filled in with appropriate setters and a build method. The generated build method will look something like:
public Person build() {
Person _thePerson = new Person()
_thePerson.first = first
_thePerson.last = last
_thePerson.born = born
return _thePerson
}The class you are creating the builder for can be any Java or Groovy class following the normal JavaBean conventions, e.g. a no-arg constructor and setters for the properties. Here is an example using a Java class:
import groovy.transform.builder.*
@Builder(builderStrategy=ExternalStrategy, forClass=javax.swing.DefaultButtonModel)
class ButtonModelBuilder {}
def model = new ButtonModelBuilder().enabled(true).pressed(true).armed(true).rollover(true).selected(true).build()
assert model.isArmed()
assert model.isPressed()
assert model.isEnabled()
assert model.isSelected()
assert model.isRollover()The generated builder can be customised using the prefix, includes, excludes and buildMethodName annotation attributes.
Here is an example illustrating various customisations:
import groovy.transform.builder.*
import groovy.transform.Canonical
@Canonical
class Person {
String first
String last
int born
}
@Builder(builderStrategy=ExternalStrategy, forClass=Person, includes=['first', 'last'], buildMethodName='create', prefix='with')
class PersonBuilder { }
def p = new PersonBuilder().withFirst('Johnny').withLast('Depp').create()
assert "$p.first $p.last" == 'Johnny Depp'The builderMethodName and builderClassName annotation attributes for @Builder aren’t applicable for this strategy.
You can use the ExternalStrategy in conjunction with @TupleConstructor. If your @Builder annotation doesn’t have
explicit includes or excludes annotation attributes but the @TupleConstructor annotation of the class you are creating
the builder for does, the ones from @TupleConstructor will be re-used for @Builder. The same applies for any
annotation aliases which combine @TupleConstructor such as @Canonical.
To use the DefaultStrategy, annotate your Groovy class using the @Builder annotation as shown in this example:
import groovy.transform.builder.Builder
@Builder
class Person {
String firstName
String lastName
int age
}
def person = Person.builder().firstName("Robert").lastName("Lewandowski").age(21).build()
assert person.firstName == "Robert"
assert person.lastName == "Lewandowski"
assert person.age == 21If you want, you can customize various aspects of the building process
using the builderClassName, buildMethodName, builderMethodName, prefix, includes and excludes annotation attributes,
some of which are used in the example here:
import groovy.transform.builder.Builder
@Builder(buildMethodName='make', builderMethodName='maker', prefix='with', excludes='age')
class Person {
String firstName
String lastName
int age
}
def p = Person.maker().withFirstName("Robert").withLastName("Lewandowski").make()
assert "$p.firstName $p.lastName" == "Robert Lewandowski"This strategy also supports annotating static methods and constructors. In this case, the static method or constructor
parameters become the properties to use for building purposes and in the case of static methods, the return type
of the method becomes the target class being built. If you have more than one @Builder annotation used within
a class (at either the class, method or constructor positions) then it is up to you to ensure that the generated
helper classes and factory methods have unique names (i.e. no more than one can use the default name values).
Here is an example highlighting method and constructor usage (and also illustrating the renaming required for unique names).
import groovy.transform.builder.*
import groovy.transform.*
@ToString
@Builder
class Person {
String first, last
int born
Person(){}
@Builder(builderClassName='MovieBuilder', builderMethodName='byRoleBuilder')
Person(String roleName) {
if (roleName == 'Jack Sparrow') {
this.first = 'Johnny'; this.last = 'Depp'; this.born = 1963
}
}
@Builder(builderClassName='NameBuilder', builderMethodName='nameBuilder', prefix='having', buildMethodName='fullName')
static String join(String first, String last) {
first + ' ' + last
}
@Builder(builderClassName='SplitBuilder', builderMethodName='splitBuilder')
static Person split(String name, int year) {
def parts = name.split(' ')
new Person(first: parts[0], last: parts[1], born: year)
}
}
assert Person.splitBuilder().name("Johnny Depp").year(1963).build().toString() == 'Person(Johnny, Depp, 1963)'
assert Person.byRoleBuilder().roleName("Jack Sparrow").build().toString() == 'Person(Johnny, Depp, 1963)'
assert Person.nameBuilder().havingFirst('Johnny').havingLast('Depp').fullName() == 'Johnny Depp'
assert Person.builder().first("Johnny").last('Depp').born(1963).build().toString() == 'Person(Johnny, Depp, 1963)'The forClass annotation attribute is not supported for this strategy.
To use the InitializerStrategy, annotate your Groovy class using the @Builder annotation, and specify the strategy as shown in this example:
import groovy.transform.builder.*
import groovy.transform.*
@ToString
@Builder(builderStrategy=InitializerStrategy)
class Person {
String firstName
String lastName
int age
}Your class will be locked down to have a single public constructor taking a "fully set" initializer. It will also have a factory method to create the initializer. These are used as follows:
@CompileStatic
def firstLastAge() {
assert new Person(Person.createInitializer().firstName("John").lastName("Smith").age(21)).toString() == 'Person(John, Smith, 21)'
}
firstLastAge()Any attempt to use the initializer which doesn’t involve setting all the properties (though order is not important) will result in
a compilation error. If you don’t need this level of strictness, you don’t need to use @CompileStatic.
You can use the InitializerStrategy in conjunction with @Canonical and @Immutable. If your @Builder annotation
doesn’t have explicit includes or excludes annotation attributes but your @Canonical annotation does, the ones
from @Canonical will be re-used for @Builder. Here is an example using @Builder with @Immutable:
import groovy.transform.builder.*
import groovy.transform.*
import static groovy.transform.options.Visibility.PRIVATE
@Builder(builderStrategy=InitializerStrategy)
@Immutable
@VisibilityOptions(PRIVATE)
class Person {
String first
String last
int born
}
def publicCons = Person.constructors
assert publicCons.size() == 1
@CompileStatic
def createFirstLastBorn() {
def p = new Person(Person.createInitializer().first('Johnny').last('Depp').born(1963))
assert "$p.first $p.last $p.born" == 'Johnny Depp 1963'
}
createFirstLastBorn()The annotation attribute useSetters can be used if you have a setter which you want called as part of the
construction process. See the JavaDoc for details.
This strategy also supports annotating static methods and constructors. In this case, the static method or constructor
parameters become the properties to use for building purposes and in the case of static methods, the return type
of the method becomes the target class being built. If you have more than one @Builder annotation used within
a class (at either the class, method or constructor positions) then it is up to you to ensure that the generated
helper classes and factory methods have unique names (i.e. no more than one can use the default name values).
For an example of method and constructor usage but using the DefaultStrategy strategy, consult that strategy’s
documentation.
The annotation attribute forClass is not supported for this strategy.
@groovy.transform.AutoImplement
The @AutoImplement AST transformation supplies dummy implementations for any found abstract methods from
superclasses or interfaces. The dummy implementation is the same for all abstract methods found and can be:
-
essentially empty (exactly true for void methods and for methods with a return type, returns the default value for that type)
-
a statement that throws a specified exception (with optional message)
-
some user supplied code
The first example illustrates the default case. Our class is annotated with @AutoImplement,
has a superclass and a single interface as can be seen here:
import groovy.transform.AutoImplement
@AutoImplement
class MyNames extends AbstractList<String> implements Closeable { }A void close() method from the
Closeable interface is supplied and left empty. Implementations are also supplied
for the three abstract methods from the super class. The get, addAll and size methods
have return types of String, boolean and int respectively with default values
null, false and 0. We can use our class (and check the expected return type for one
of the methods) using the following code:
assert new MyNames().size() == 0It is also worthwhile examining the equivalent generated code:
class MyNames implements Closeable extends AbstractList<String> {
String get(int param0) {
return null
}
boolean addAll(Collection<? extends String> param0) {
return false
}
void close() throws Exception {
}
int size() {
return 0
}
}The second example illustrates the simplest exception case. Our class is annotated with @AutoImplement,
has a superclass and an annotation attribute indicates that an IOException should be thrown if any of
our "dummy" methods are called. Here is the class definition:
@AutoImplement(exception=IOException)
class MyWriter extends Writer { }We can use the class (and check the expected exception is thrown for one of the methods) using the following code:
import static groovy.test.GroovyAssert.shouldFail
shouldFail(IOException) {
new MyWriter().flush()
}It is also worthwhile examining the equivalent generated code where three void methods have been provided all of which throw the supplied exception:
class MyWriter extends Writer {
void flush() throws IOException {
throw new IOException()
}
void write(char[] param0, int param1, int param2) throws IOException {
throw new IOException()
}
void close() throws Exception {
throw new IOException()
}
}The third example illustrates the exception case with a supplied message. Our class is annotated with @AutoImplement,
implements an interface, and has annotation attributes to indicate that an UnsupportedOperationException with
Not supported by MyIterator as the message should be thrown for any supplied methods. Here is the class definition:
@AutoImplement(exception=UnsupportedOperationException, message='Not supported by MyIterator')
class MyIterator implements Iterator<String> { }We can use the class (and check the expected exception is thrown and has the correct message for one of the methods) using the following code:
def ex = shouldFail(UnsupportedOperationException) {
new MyIterator().hasNext()
}
assert ex.message == 'Not supported by MyIterator'It is also worthwhile examining the equivalent generated code where three void methods have been provided all of which throw the supplied exception:
class MyIterator implements Iterator<String> {
boolean hasNext() {
throw new UnsupportedOperationException('Not supported by MyIterator')
}
String next() {
throw new UnsupportedOperationException('Not supported by MyIterator')
}
}The fourth example illustrates the case of user supplied code. Our class is annotated with @AutoImplement,
implements an interface, has an explicitly overridden hasNext method, and has an annotation attribute containing the
supplied code for any supplied methods. Here is the class definition:
@AutoImplement(code = { throw new UnsupportedOperationException('Should never be called but was called on ' + new Date()) })
class EmptyIterator implements Iterator<String> {
boolean hasNext() { false }
}We can use the class (and check the expected exception is thrown and has a message of the expected form) using the following code:
def ex = shouldFail(UnsupportedOperationException) {
new EmptyIterator().next()
}
assert ex.message.startsWith('Should never be called but was called on ')It is also worthwhile examining the equivalent generated code where the next method has been supplied:
class EmptyIterator implements java.util.Iterator<String> {
boolean hasNext() {
false
}
String next() {
throw new UnsupportedOperationException('Should never be called but was called on ' + new Date())
}
}@groovy.transform.NullCheck
The @NullCheck AST transformation adds null-check guard statements to constructors and methods
which cause those methods to fail early when supplied with null arguments.
It can be seen as a form of defensive programming.
The annotation can be added to individual methods or constructors, or to the class
in which case it will apply to all methods/constructors.
@NullCheck
String longerOf(String first, String second) {
first.size() >= second.size() ? first : second
}
assert longerOf('cat', 'canary') == 'canary'
def ex = shouldFail(IllegalArgumentException) {
longerOf('cat', null)
}
assert ex.message == 'second cannot be null'2.1.2. Class design annotations
This category of annotations are aimed at simplifying the implementation of well-known design patterns (delegation, singleton, …) by using a declarative style.
@groovy.transform.BaseScript
@BaseScript is used within scripts to indicate that the script should
extend from a custom script base class rather than groovy.lang.Script.
See the documentation for domain specific languages for further details.
@groovy.lang.Delegate
The @Delegate AST transformation aims at implementing the delegation design pattern. In the following class:
class Event {
@Delegate Date when
String title
}The when property is annotated with @Delegate, meaning that the Event class will delegate calls to Date methods
to the when property. In this case, the generated code looks like this:
class Event {
Date when
String title
boolean before(Date other) {
when.before(other)
}
// ...
}Then you can call the before method, for example, directly on the Event class:
def ev = new Event(title:'Groovy keynote', when: Date.parse('yyyy/MM/dd', '2013/09/10'))
def now = new Date()
assert ev.before(now)Instead of annotating a property (or field), you can also annotate a method. In this case, the method can be thought of as a getter or factory method for the delegate. As an example, here is a class which (rather unusually) has a pool of delegates which are accessed in a round-robin fashion:
class Test {
private int robinCount = 0
private List<List> items = [[0], [1], [2]]
@Delegate
List getRoundRobinList() {
items[robinCount++ % items.size()]
}
void checkItems(List<List> testValue) {
assert items == testValue
}
}Here is an example usage of that class:
def t = new Test()
t << 'fee'
t << 'fi'
t << 'fo'
t << 'fum'
t.checkItems([[0, 'fee', 'fum'], [1, 'fi'], [2, 'fo']])Using a standard list in this round-robin fashion would violate many expected properties of lists, so don’t expect the above class to do anything useful beyond this trivial example.
The behavior of the @Delegate AST transformation can be changed using the following parameters:
| Attribute | Default value | Description | Example |
|---|---|---|---|
interfaces |
True |
Should the interfaces implemented by the field be implemented by the class too |
|
deprecated |
false |
If true, also delegates methods annotated with @Deprecated |
|
methodAnnotations |
False |
Whether to carry over annotations from the methods of the delegate to your delegating method. |
|
parameterAnnotations |
False |
Whether to carry over annotations from the method parameters of the delegate to your delegating method. |
|
excludes |
Empty array |
A list of methods to be excluded from delegation. For more fine-grained control, see also |
|
includes |
Undefined marker array (indicates all methods) |
A list of methods to be included in delegation. For more
fine-grained
control, see also |
|
excludeTypes |
Empty array |
A list of interfaces containing method signatures to be excluded from delegation |
|
includeTypes |
Undefined marker array (indicates no list be default) |
A list of interfaces containing method signatures to be included in delegation |
|
allNames |
False |
Should the delegate pattern be also applied to methods with internal names |
|
@groovy.transform.Immutable
The @Immutable meta-annotation combines the following annotations:
The @Immutable meta-annotation simplifies the creation of immutable classes. Immutable classes are useful
since they are often easier to reason about and are inherently thread-safe.
See Effective Java, Minimize Mutability for all the details
about how to achieve immutable classes in Java. The @Immutable meta-annotation does most of the things described
in Effective Java for you automatically.
To use the meta-annotation, all you have to do is annotate the class like in the following example:
import groovy.transform.Immutable
@Immutable
class Point {
int x
int y
}One of the requirements for immutable classes is that there is no way to modify any state information within the class.
One requirement to achieve this is to use immutable classes for each property or alternatively perform special coding
such as defensive copy in and defensive copy out for any mutable properties within the constructors
and property getters. Between @ImmutableBase, @MapConstructor and @TupleConstructor properties
are either identified as immutable or the special coding for numerous known cases is handled automatically.
Various mechanisms are provided for you to extend the handled property types which are allowed. See
@ImmutableOptions and @KnownImmutable for details.
The results of applying @Immutable to a class are pretty similar to those of
applying the @Canonical meta-annotation but the generated class will have extra
logic to handle immutability. You will observe this by, for instance, trying to modify a property
which will result in a ReadOnlyPropertyException being thrown since the backing field for the property
will have been automatically made final.
The @Immutable meta-annotation supports the configuration options found in the annotations
it aggregates. See those annotations for more details.
@groovy.transform.ImmutableBase
Immutable classes generated with @ImmutableBase are automatically made final. Also, the type of each property is checked
and various checks are made on the class, for example, public instance fields currently aren’t allowed. It also generates
a copyWith constructor if desired.
The following annotation attribute is supported:
| Attribute | Default value | Description | Example |
|---|---|---|---|
copyWith |
false |
A boolean whether to generate a |
|
@groovy.transform.PropertyOptions
This annotation allows you to specify a custom property handler to be used by transformations
during class construction. It is ignored by the main Groovy compiler but is referenced by other transformations
like @TupleConstructor, @MapConstructor, and @ImmutableBase. It is frequently used behind the
scenes by the @Immutable meta-annotation.
@groovy.transform.VisibilityOptions
This annotation allows you to specify a custom visibility for a construct generated by another transformation.
It is ignored by the main Groovy compiler but is referenced by other transformations
like @TupleConstructor, @MapConstructor, and @NamedVariant.
@groovy.transform.ImmutableOptions
Groovy’s immutability support relies on a predefined list of known immutable classes (like java.net.URI or java.lang.String
and fails if you use a type which is not in that list, you are allowed to add to the list of known immutable types
thanks to the following annotation attributes of the @ImmutableOptions annotation:
| Attribute | Default value | Description | Example |
|---|---|---|---|
knownImmutableClasses |
Empty list |
A list of classes which are deemed immutable. |
|
knownImmutables |
Empty list |
A list of property names which are deemed immutable. |
|
If you deem a type as immutable and it isn’t one of the ones automatically handled, then it is up to you to correctly code that class to ensure immutability.
@groovy.transform.KnownImmutable
The @KnownImmutable annotation isn’t actually one that triggers any AST transformations. It is simply
a marker annotation. You can annotate your classes with the annotation (including Java classes) and they
will be recognized as acceptable types for members within an immutable class. This saves you having to
explicitly use the knownImmutables or knownImmutableClasses annotation attributes from @ImmutableOptions.
@groovy.transform.Memoized
The @Memoized AST transformations simplifies the implementation of caching by allowing the result of method calls
to be cached just by annotating the method with @Memoized. Let’s imagine the following method:
long longComputation(int seed) {
// slow computation
Thread.sleep(100*seed)
System.nanoTime()
}This emulates a long computation, based on the actual parameters of the method. Without @Memoized, each method call
would take several seconds plus it would return a random result:
def x = longComputation(1)
def y = longComputation(1)
assert x!=yAdding @Memoized changes the semantics of the method by adding caching, based on the parameters:
@Memoized
long longComputation(int seed) {
// slow computation
Thread.sleep(100*seed)
System.nanoTime()
}
def x = longComputation(1) // returns after 100 milliseconds
def y = longComputation(1) // returns immediately
def z = longComputation(2) // returns after 200 milliseconds
assert x==y
assert x!=zThe size of the cache can be configured using two optional parameters:
-
protectedCacheSize: the number of results which are guaranteed not to be cleared after garbage collection
-
maxCacheSize: the maximum number of results that can be kept in memory
By default, the size of the cache is unlimited and no cache result is protected from garbage collection. Setting a protectedCacheSize>0 would create an unlimited cache with some results protected. Setting maxCacheSize>0 would create a limited cache but without any protection from garbage protection. Setting both would create a limited, protected cache.
@groovy.transform.TailRecursive
The @TailRecursive annotation can be used to automatically transform a recursive call at the end of a method
into an equivalent iterative version of the same code. This avoids stack overflow due to too many recursive calls.
Below is an example of use when calculating factorial:
import groovy.transform.CompileStatic
import groovy.transform.TailRecursive
@CompileStatic
class Factorial {
@TailRecursive
static BigInteger factorial( BigInteger i, BigInteger product = 1) {
if( i == 1) {
return product
}
return factorial(i-1, product*i)
}
}
assert Factorial.factorial(1) == 1
assert Factorial.factorial(3) == 6
assert Factorial.factorial(5) == 120
assert Factorial.factorial(50000).toString().size() == 213237 // Big number and no Stack OverflowCurrently, the annotation will only work for self-recursive method calls, i.e. a single recursive call to the exact same method again.
Consider using Closures and trampoline() if you have a scenario involving simple mutual recursion.
Also note that only non-void methods are currently handled (void calls will result in a compilation error).
| Currently, some forms of method overloading can trick the compiler, and some non-tail recursive calls are erroneously treated as tail recursive. |
@groovy.lang.Singleton
The @Singleton annotation can be used to implement the singleton design pattern on a class. The singleton instance
is defined eagerly by default, using class initialization, or lazily, in which case the field is initialized using
double-checked locking.
@Singleton
class GreetingService {
String greeting(String name) { "Hello, $name!" }
}
assert GreetingService.instance.greeting('Bob') == 'Hello, Bob!'By default, the singleton is created eagerly when the class is initialized and available through the instance property.
It is possible to change the name of the singleton using the property parameter:
@Singleton(property='theOne')
class GreetingService {
String greeting(String name) { "Hello, $name!" }
}
assert GreetingService.theOne.greeting('Bob') == 'Hello, Bob!'And it is also possible to make initialization lazy using the lazy parameter:
class Collaborator {
public static boolean init = false
}
@Singleton(lazy=true,strict=false)
class GreetingService {
static void init() {}
GreetingService() {
Collaborator.init = true
}
String greeting(String name) { "Hello, $name!" }
}
GreetingService.init() // make sure class is initialized
assert Collaborator.init == false
GreetingService.instance
assert Collaborator.init == true
assert GreetingService.instance.greeting('Bob') == 'Hello, Bob!'In this example, we also set the strict parameter to false, which allows us to define our own constructor.
@groovy.lang.Mixin
Deprecated. Consider using traits instead.
2.1.3. Logging improvements
Groovy provides a family of AST transformations that help with integration of the most widely used logging frameworks. There is a transform and associated annotation for each of the common frameworks. These transforms provide a streamlined declarative approach to using the logging framework. In each case, the transform will:
-
add a static final
logfield to the annotated class corresponding to the logger -
wrap all calls to
log.level()into the appropriatelog.isLevelEnabledguard, depending on the underlying framework
Those transformations support two parameters:
-
value(defaultlog) corresponds to the name of the logger field -
category(defaults to the class name) is the name of the logger category
It’s worth noting that annotating a class with one of those annotations doesn’t prevent you from using the logging framework using the normal long-hand approach.
@groovy.util.logging.Log
The first logging AST transformation available is the @Log annotation which relies on the JDK logging framework. Writing:
@groovy.util.logging.Log
class Greeter {
void greet() {
log.info 'Called greeter'
println 'Hello, world!'
}
}is equivalent to writing:
import java.util.logging.Level
import java.util.logging.Logger
class Greeter {
private static final Logger log = Logger.getLogger(Greeter.name)
void greet() {
if (log.isLoggable(Level.INFO)) {
log.info 'Called greeter'
}
println 'Hello, world!'
}
}@groovy.util.logging.Commons
Groovy supports the Apache Commons Logging framework using the
@Commons annotation. Writing:
@groovy.util.logging.Commons
class Greeter {
void greet() {
log.debug 'Called greeter'
println 'Hello, world!'
}
}is equivalent to writing:
import org.apache.commons.logging.LogFactory
import org.apache.commons.logging.Log
class Greeter {
private static final Log log = LogFactory.getLog(Greeter)
void greet() {
if (log.isDebugEnabled()) {
log.debug 'Called greeter'
}
println 'Hello, world!'
}
}You still need to add the appropriate commons-logging jar to your classpath.
@groovy.util.logging.Log4j
Groovy supports the Apache Log4j 1.x framework using the
@Log4j annotation. Writing:
@groovy.util.logging.Log4j
class Greeter {
void greet() {
log.debug 'Called greeter'
println 'Hello, world!'
}
}is equivalent to writing:
import org.apache.log4j.Logger
class Greeter {
private static final Logger log = Logger.getLogger(Greeter)
void greet() {
if (log.isDebugEnabled()) {
log.debug 'Called greeter'
}
println 'Hello, world!'
}
}You still need to add the appropriate log4j jar to your classpath. This annotation can also be used with the compatible reload4j log4j drop-in replacement, just use the jar from that project instead of a log4j jar.
@groovy.util.logging.Log4j2
Groovy supports the Apache Log4j 2.x framework using the
@Log4j2 annotation. Writing:
@groovy.util.logging.Log4j2
class Greeter {
void greet() {
log.debug 'Called greeter'
println 'Hello, world!'
}
}is equivalent to writing:
import org.apache.logging.log4j.LogManager
import org.apache.logging.log4j.Logger
class Greeter {
private static final Logger log = LogManager.getLogger(Greeter)
void greet() {
if (log.isDebugEnabled()) {
log.debug 'Called greeter'
}
println 'Hello, world!'
}
}You still need to add the appropriate log4j2 jar to your classpath.
@groovy.util.logging.Slf4j
Groovy supports the Simple Logging Facade for Java (SLF4J) framework using the
@Slf4j annotation. Writing:
@groovy.util.logging.Slf4j
class Greeter {
void greet() {
log.debug 'Called greeter'
println 'Hello, world!'
}
}is equivalent to writing:
import org.slf4j.LoggerFactory
import org.slf4j.Logger
class Greeter {
private static final Logger log = LoggerFactory.getLogger(Greeter)
void greet() {
if (log.isDebugEnabled()) {
log.debug 'Called greeter'
}
println 'Hello, world!'
}
}You still need to add the appropriate slf4j jar(s) to your classpath.
@groovy.util.logging.PlatformLog
Groovy supports the Java Platform Logging API and Service
framework using the @PlatformLog annotation. Writing:
@groovy.util.logging.PlatformLog
class Greeter {
void greet() {
log.info 'Called greeter'
println 'Hello, world!'
}
}is equivalent to writing:
import java.lang.System.Logger
import java.lang.System.LoggerFinder
import static java.lang.System.Logger.Level.INFO
class Greeter {
private static final transient Logger log =
LoggerFinder.loggerFinder.getLogger(Greeter.class.name, Greeter.class.module)
void greet() {
log.log INFO, 'Called greeter'
println 'Hello, world!'
}
}You need to be using JDK 9+ to use this capability.
2.1.4. Declarative concurrency
The Groovy language provides a set of annotations aimed at simplifying common concurrency patterns in a declarative approach.
@groovy.transform.Synchronized
The @Synchronized AST transformations works in a similar way to the synchronized keyword but locks on different
objects for safer concurrency. It can be applied on any method or static method:
import groovy.transform.Synchronized
import java.util.concurrent.Executors
import java.util.concurrent.TimeUnit
class Counter {
int cpt
@Synchronized
int incrementAndGet() {
cpt++
}
int get() {
cpt
}
}Writing this is equivalent to creating a lock object and wrapping the whole method into a synchronized block:
class Counter {
int cpt
private final Object $lock = new Object()
int incrementAndGet() {
synchronized($lock) {
cpt++
}
}
int get() {
cpt
}
}By default, @Synchronized creates a field named $lock (or $LOCK for a static method) but you can make it use any
field you want by specifying the value attribute, like in the following example:
import groovy.transform.Synchronized
import java.util.concurrent.Executors
import java.util.concurrent.TimeUnit
class Counter {
int cpt
private final Object myLock = new Object()
@Synchronized('myLock')
int incrementAndGet() {
cpt++
}
int get() {
cpt
}
}@groovy.transform.WithReadLock and @groovy.transform.WithWriteLock
The @WithReadLock AST transformation works in conjunction with the @WithWriteLock transformation
to provide read/write synchronization using the ReentrantReadWriteLock facility that the JDK provides. The annotation
can be added to a method or a static method. It will transparently create a $reentrantLock final field (or
$REENTRANTLOCK for a static method) and proper synchronization code will be added. For example, the following code:
import groovy.transform.WithReadLock
import groovy.transform.WithWriteLock
class Counters {
public final Map<String,Integer> map = [:].withDefault { 0 }
@WithReadLock
int get(String id) {
map.get(id)
}
@WithWriteLock
void add(String id, int num) {
Thread.sleep(200) // emulate long computation
map.put(id, map.get(id)+num)
}
}is equivalent to this:
import groovy.transform.WithReadLock as WithReadLock
import groovy.transform.WithWriteLock as WithWriteLock
public class Counters {
private final Map<String, Integer> map
private final java.util.concurrent.locks.ReentrantReadWriteLock $reentrantlock
public int get(java.lang.String id) {
$reentrantlock.readLock().lock()
try {
map.get(id)
}
finally {
$reentrantlock.readLock().unlock()
}
}
public void add(java.lang.String id, int num) {
$reentrantlock.writeLock().lock()
try {
java.lang.Thread.sleep(200)
map.put(id, map.get(id) + num )
}
finally {
$reentrantlock.writeLock().unlock()
}
}
}Both @WithReadLock and @WithWriteLock support specifying an alternative lock object. In that case, the referenced
field must be declared by the user, like in the following alternative:
import groovy.transform.WithReadLock
import groovy.transform.WithWriteLock
import java.util.concurrent.locks.ReentrantReadWriteLock
class Counters {
public final Map<String,Integer> map = [:].withDefault { 0 }
private final ReentrantReadWriteLock customLock = new ReentrantReadWriteLock()
@WithReadLock('customLock')
int get(String id) {
map.get(id)
}
@WithWriteLock('customLock')
void add(String id, int num) {
Thread.sleep(200) // emulate long computation
map.put(id, map.get(id)+num)
}
}For details
-
See Javadoc for groovy.transform.WithReadLock
-
See Javadoc for groovy.transform.WithWriteLock
2.1.5. Easier cloning and externalizing
Groovy provides two annotations aimed at facilitating the implementation of Cloneable and Externalizable interfaces,
respectively named @AutoClone and @AutoExternalize.
@groovy.transform.AutoClone
The @AutoClone annotation is aimed at implementing the @java.lang.Cloneable interface using various strategies, thanks to the style parameter:
-
the default
AutoCloneStyle.CLONEstrategy callssuper.clone()first thenclone()on each cloneable property -
the
AutoCloneStyle.SIMPLEstrategy uses a regular constructor call and copies properties from the source to the clone -
the
AutoCloneStyle.COPY_CONSTRUCTORstrategy creates and uses a copy constructor -
the
AutoCloneStyle.SERIALIZATIONstrategy uses serialization (or externalization) to clone the object
Each of those strategies have pros and cons which are discussed in the Javadoc for groovy.transform.AutoClone and groovy.transform.AutoCloneStyle .
For example, the following example:
import groovy.transform.AutoClone
@AutoClone
class Book {
String isbn
String title
List<String> authors
Date publicationDate
}is equivalent to this:
class Book implements Cloneable {
String isbn
String title
List<String> authors
Date publicationDate
public Book clone() throws CloneNotSupportedException {
Book result = super.clone()
result.authors = authors instanceof Cloneable ? (List) authors.clone() : authors
result.publicationDate = publicationDate.clone()
result
}
}Note that the String properties aren’t explicitly handled because Strings are immutable and the clone() method from Object will copy the String references. The same would apply to primitive fields and most of the concrete subclasses of java.lang.Number.
In addition to cloning styles, @AutoClone supports multiple options:
| Attribute | Default value | Description | Example |
|---|---|---|---|
excludes |
Empty list |
A list of property or field names that need to be excluded from cloning. A string consisting of a comma-separated field/property names is also allowed. See groovy.transform.AutoClone#excludes for details |
|
includeFields |
false |
By default, only properties are cloned. Setting this flag to true will also clone fields. |
|
@groovy.transform.AutoExternalize
The @AutoExternalize AST transformation will assist in the creation of java.io.Externalizable classes. It will
automatically add the interface to the class and generate the writeExternal and readExternal methods. For example, this
code:
import groovy.transform.AutoExternalize
@AutoExternalize
class Book {
String isbn
String title
float price
}will be converted into:
class Book implements java.io.Externalizable {
String isbn
String title
float price
void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(isbn)
out.writeObject(title)
out.writeFloat( price )
}
public void readExternal(ObjectInput oin) {
isbn = (String) oin.readObject()
title = (String) oin.readObject()
price = oin.readFloat()
}
}The @AutoExternalize annotation supports two parameters which will let you slightly customize its behavior:
| Attribute | Default value | Description | Example |
|---|---|---|---|
excludes |
Empty list |
A list of property or field names that need to be excluded from externalizing. A string consisting of a comma-separated field/property names is also allowed. See groovy.transform.AutoExternalize#excludes for details |
|
includeFields |
false |
By default, only properties are externalized. Setting this flag to true will also clone fields. |
|
2.1.6. Safer scripting
The Groovy language makes it easy to execute user scripts at runtime (for example using groovy.lang.GroovyShell), but how do you make sure that a script won’t eat all CPU (infinite loops) or that concurrent scripts won’t slowly consume all available threads of a thread pool? Groovy provides several annotations which are aimed towards safer scripting, generating code which will for example allow you to interrupt execution automatically.
@groovy.transform.ThreadInterrupt
One complicated situation in the JVM world is when a thread can’t be stopped. The Thread#stop method exists but is
deprecated (and isn’t reliable) so your only chance lies in Thread#interrupt. Calling the latter will set the
interrupt flag on the thread, but it will not stop the execution of the thread. This is problematic because it’s the
responsibility of the code executing in the thread to check the interrupt flag and properly exit. This makes sense when
you, as a developer, know that the code you are executing is meant to be run in an independent thread, but in general,
you don’t know it. It’s even worse with user scripts, who might not even know what a thread is (think of DSLs).
@ThreadInterrupt simplifies this by adding thread interruption checks at critical places in the code:
-
loops (for, while)
-
first instruction of a method
-
first instruction of a closure body
Let’s imagine the following user script:
while (true) {
i++
}This is an obvious infinite loop. If this code executes in its own thread, interrupting wouldn’t help: if you join on
the thread, then the calling code would be able to continue, but the thread would still be alive, running in background
without any ability for you to stop it, slowly causing thread starvation.
One possibility to work around this is to set up your shell this way:
def config = new CompilerConfiguration()
config.addCompilationCustomizers(
new ASTTransformationCustomizer(ThreadInterrupt)
)
def binding = new Binding(i:0)
def shell = new GroovyShell(binding,config)The shell is then configured to automatically apply the @ThreadInterrupt AST transformations on all scripts. This allows
you to execute user scripts this way:
def t = Thread.start {
shell.evaluate(userCode)
}
t.join(1000) // give at most 1000ms for the script to complete
if (t.alive) {
t.interrupt()
}The transformation automatically modified user code like this:
while (true) {
if (Thread.currentThread().interrupted) {
throw new InterruptedException('The current thread has been interrupted.')
}
i++
}The check which is introduced inside the loop guarantees that if the interrupt flag is set on the current thread, an
exception will be thrown, interrupting the execution of the thread.
@ThreadInterrupt supports multiple options that will let you further customize the behavior of the transformation:
| Attribute | Default value | Description | Example |
|---|---|---|---|
thrown |
|
Specifies the type of exception which is thrown if the thread is interrupted. |
|
checkOnMethodStart |
true |
Should an interruption check be inserted at the beginning of each method body. See groovy.transform.ThreadInterrupt for details. |
|
applyToAllClasses |
true |
Should the transformation be applied on all classes of the same source unit (in the same source file). See groovy.transform.ThreadInterrupt for details. |
|
applyToAllMembers |
true |
Should the transformation be applied on all members of class. See groovy.transform.ThreadInterrupt for details. |
|
@groovy.transform.TimedInterrupt
The @TimedInterrupt AST transformation tries to solve a slightly different problem from @groovy.transform.ThreadInterrupt: instead of checking the interrupt flag of the thread, it will automatically
throw an exception if the thread has been running for too long.
This annotation does not spawn a monitoring thread. Instead, it works in a similar manner as @ThreadInterrupt by placing checks at appropriate places in the code. This means that if you
have a thread blocked by I/O, it will not be interrupted.
|
Imagine the following user code:
def fib(int n) { n<2?n:fib(n-1)+fib(n-2) }
result = fib(600)The implementation of the famous Fibonacci number computation here is far from optimized. If it is called with a high n value, it can take minutes to answer. With @TimedInterrupt, you can
choose how long a script is allowed to run. The following setup code will allow the user script to run for 1 second at max:
def config = new CompilerConfiguration()
config.addCompilationCustomizers(
new ASTTransformationCustomizer(value:1, TimedInterrupt)
)
def binding = new Binding(result:0)
def shell = new GroovyShell(this.class.classLoader, binding,config)This code is equivalent to annotating a class with @TimedInterrupt like this:
@TimedInterrupt(value=1, unit=TimeUnit.SECONDS)
class MyClass {
def fib(int n) {
n<2?n:fib(n-1)+fib(n-2)
}
}@TimedInterrupt supports multiple options that will let you further customize the behavior of the transformation:
| Attribute | Default value | Description | Example |
|---|---|---|---|
value |
Long.MAX_VALUE |
Used in combination with |
|
unit |
TimeUnit.SECONDS |
Used in combination with |
|
thrown |
|
Specifies the type of exception which is thrown if timeout is reached. |
|
checkOnMethodStart |
true |
Should an interruption check be inserted at the beginning of each method body. See groovy.transform.TimedInterrupt for details. |
|
applyToAllClasses |
true |
Should the transformation be applied on all classes of the same source unit (in the same source file). See groovy.transform.TimedInterrupt for details. |
|
applyToAllMembers |
true |
Should the transformation be applied on all members of class. See groovy.transform.TimedInterrupt for details. |
|
@TimedInterrupt is currently not compatible with static methods!
|
@groovy.transform.ConditionalInterrupt
The last annotation for safer scripting is the base annotation when you want to interrupt a script using a custom strategy. In particular, this is the annotation of choice if you
want to use resource management (limit the number of calls to an API, …). In the following example, user code is using an infinite loop, but @ConditionalInterrupt will allow us
to check a quota manager and interrupt automatically the script:
@ConditionalInterrupt({Quotas.disallow('user')})
class UserCode {
void doSomething() {
int i=0
while (true) {
println "Consuming resources ${++i}"
}
}
}The quota checking is very basic here, but it can be any code:
class Quotas {
static def quotas = [:].withDefault { 10 }
static boolean disallow(String userName) {
println "Checking quota for $userName"
(quotas[userName]--)<0
}
}We can make sure @ConditionalInterrupt works properly using this test code:
assert Quotas.quotas['user'] == 10
def t = Thread.start {
new UserCode().doSomething()
}
t.join(5000)
assert !t.alive
assert Quotas.quotas['user'] < 0Of course, in practice, it is unlikely that @ConditionalInterrupt will be itself added by hand on user code. It can be injected in a similar manner as the example shown in the
ThreadInterrupt section, using the org.codehaus.groovy.control.customizers.ASTTransformationCustomizer :
def config = new CompilerConfiguration()
def checkExpression = new ClosureExpression(
Parameter.EMPTY_ARRAY,
new ExpressionStatement(
new MethodCallExpression(new ClassExpression(ClassHelper.make(Quotas)), 'disallow', new ConstantExpression('user'))
)
)
config.addCompilationCustomizers(
new ASTTransformationCustomizer(value: checkExpression, ConditionalInterrupt)
)
def shell = new GroovyShell(this.class.classLoader,new Binding(),config)
def userCode = """
int i=0
while (true) {
println "Consuming resources \\${++i}"
}
"""
assert Quotas.quotas['user'] == 10
def t = Thread.start {
shell.evaluate(userCode)
}
t.join(5000)
assert !t.alive
assert Quotas.quotas['user'] < 0@ConditionalInterrupt supports multiple options that will let you further customize the behavior of the transformation:
| Attribute | Default value | Description | Example |
|---|---|---|---|
value |
The closure which will be called to check if execution is allowed. If the closure returns false, execution is allowed. If it returns true, then an exception will be thrown. |
|
|
thrown |
|
Specifies the type of exception which is thrown if execution should be aborted. |
|
checkOnMethodStart |
true |
Should an interruption check be inserted at the beginning of each method body. See groovy.transform.ConditionalInterrupt for details. |
|
applyToAllClasses |
true |
Should the transformation be applied on all classes of the same source unit (in the same source file). See groovy.transform.ConditionalInterrupt for details. |
|
applyToAllMembers |
true |
Should the transformation be applied on all members of class. See groovy.transform.ConditionalInterrupt for details. |
|
2.1.7. Compiler directives
This category of AST transformations groups annotations which have a direct impact on the semantics of the code, rather than focusing on code generation. With that regards, they can be seen as compiler directives that either change the behavior of a program at compile time or runtime.
@groovy.transform.Field
The @Field annotation only makes sense in the context of a script and aims at solving a common scoping error with
scripts. The following example will for example fail at runtime:
def x
String line() {
"="*x
}
x=3
assert "===" == line()
x=5
assert "=====" == line()The error that is thrown may be difficult to interpret: groovy.lang.MissingPropertyException: No such property: x. The reason is that scripts are compiled to classes and the script body is itself compiled as a single run() method. Methods which are defined in the scripts are independent, so the code above is equivalent to this:
class MyScript extends Script {
String line() {
"="*x
}
public def run() {
def x
x=3
assert "===" == line()
x=5
assert "=====" == line()
}
}So def x is effectively interpreted as a local variable, outside of the scope of the line method. The @Field AST transformation aims at fixing this
by changing the scope of the variable to a field of the enclosing script:
@Field def x
String line() {
"="*x
}
x=3
assert "===" == line()
x=5
assert "=====" == line()The resulting, equivalent, code is now:
class MyScript extends Script {
def x
String line() {
"="*x
}
public def run() {
x=3
assert "===" == line()
x=5
assert "=====" == line()
}
}@groovy.transform.PackageScope
By default, Groovy visibility rules imply that if you create a field without specifying a modifier, then the field is interpreted as a property:
class Person {
String name // this is a property
}Should you want to create a package private field instead of a property (private field+getter/setter), then annotate your field with @PackageScope:
class Person {
@PackageScope String name // not a property anymore
}The @PackageScope annotation can also be used for classes, methods and constructors. In addition, by specifying a list
of PackageScopeTarget values as the annotation attribute at the class level, all members within that class that don’t
have an explicit modifier and match the provided PackageScopeTarget will remain package protected. For example to apply
to fields within a class use the following annotation:
import static groovy.transform.PackageScopeTarget.FIELDS
@PackageScope(FIELDS)
class Person {
String name // not a property, package protected
Date dob // not a property, package protected
private int age // explicit modifier, so won't be touched
}The @PackageScope annotation is seldom used as part of normal Groovy conventions but is sometimes useful
for factory methods that should be visible internally within a package or for methods or constructors provided
for testing purposes, or when integrating with third-party libraries which require such visibility conventions.
@groovy.transform.Final
@Final is essentially an alias for the final modifier.
The intention is that you would almost never use the @Final annotation directly (just use final).
However, when creating meta-annotations that should apply
the final modifier to the node being annotated, you can mix in @Final, e.g..
@AnnotationCollector([Singleton,Final]) @interface MySingleton {}
@MySingleton
class GreetingService {
String greeting(String name) { "Hello, $name!" }
}
assert GreetingService.instance.greeting('Bob') == 'Hello, Bob!'
assert Modifier.isFinal(GreetingService.modifiers)@groovy.transform.AutoFinal
The @AutoFinal annotation instructs the compiler to automatically insert the final modifier
in numerous places within the annotated node. If applied on a method (or constructor), the parameters
for that method (or constructor) will be marked as final. If applied on a class definition, the same
treatment will occur for all declared methods and constructors within that class.
It is often considered bad practice to reassign parameters of a method or constructor with its body.
By adding the final modifier to all parameter declarations you can avoid this practice entirely.
Some programmers feel that adding final everywhere increases the amount of boilerplate code and makes the
method signatures somewhat noisy. An alternative might instead be to use a code review process or apply
a codenarc rule
to give warnings if that practice is observed but these alternatives might lead to delayed feedback during
quality checking rather than within the IDE or during compilation. The @AutoFinal annotation aims to
maximise compiler/IDE feedback while retaining succinct code with minimum boilerplate noise.
The following example illustrates applying the annotation at the class level:
import groovy.transform.AutoFinal
@AutoFinal
class Person {
private String first, last
Person(String first, String last) {
this.first = first
this.last = last
}
String fullName(String separator) {
"$first$separator$last"
}
String greeting(String salutation) {
"$salutation, $first"
}
}In this example, the two parameters for the constructor and the single parameter for
both the fullname and greeting methods will be final. Attempts to modify those parameters within the
constructor or method bodies will be flagged by the compiler.
The following example illustrates applying the annotation at the method level:
class Calc {
@AutoFinal
int add(int a, int b) { a + b }
int mult(int a, int b) { a * b }
}Here, the add method will have final parameters but the mult method will remain unchanged.
@groovy.transform.AnnotationCollector
@AnnotationCollector allows the creation of meta-annotations, which are described in a dedicated section.
@groovy.transform.TypeChecked
@TypeChecked activates compile-time type checking on your Groovy code. See section on type checking for details.
@groovy.transform.CompileStatic
@CompileStatic activates static compilation on your Groovy code. See section on type checking for details.
@groovy.transform.CompileDynamic
@CompileDynamic disables static compilation on parts of your Groovy code. See section on type checking for details.
@groovy.lang.DelegatesTo
@DelegatesTo is not, technically speaking, an AST transformation. It is aimed at documenting code and helping the compiler in case you are
using type checking or static compilation. The annotation is described thoroughly in the
DSL section of this guide.
@groovy.transform.SelfType
@SelfType is not an AST transformation but rather a marker interface used
with traits. See the traits documentation for further details.
2.1.8. Swing patterns
@groovy.beans.Bindable
@Bindable is an AST transformation that transforms a regular property into a bound property (according to the JavaBeans specification).
The @Bindable annotation can be placed on a property or a class. To convert all properties of a class into bound properties, on can annotate the class like in this example:
import groovy.beans.Bindable
@Bindable
class Person {
String name
int age
}This is equivalent to writing this:
import java.beans.PropertyChangeListener
import java.beans.PropertyChangeSupport
class Person {
final private PropertyChangeSupport this$propertyChangeSupport
String name
int age
public void addPropertyChangeListener(PropertyChangeListener listener) {
this$propertyChangeSupport.addPropertyChangeListener(listener)
}
public void addPropertyChangeListener(String name, PropertyChangeListener listener) {
this$propertyChangeSupport.addPropertyChangeListener(name, listener)
}
public void removePropertyChangeListener(PropertyChangeListener listener) {
this$propertyChangeSupport.removePropertyChangeListener(listener)
}
public void removePropertyChangeListener(String name, PropertyChangeListener listener) {
this$propertyChangeSupport.removePropertyChangeListener(name, listener)
}
public void firePropertyChange(String name, Object oldValue, Object newValue) {
this$propertyChangeSupport.firePropertyChange(name, oldValue, newValue)
}
public PropertyChangeListener[] getPropertyChangeListeners() {
return this$propertyChangeSupport.getPropertyChangeListeners()
}
public PropertyChangeListener[] getPropertyChangeListeners(String name) {
return this$propertyChangeSupport.getPropertyChangeListeners(name)
}
}@Bindable therefore removes a lot of boilerplate from your class, dramatically increasing readability. If the annotation is put on a single property, only that property is bound:
import groovy.beans.Bindable
class Person {
String name
@Bindable int age
}@groovy.beans.ListenerList
The @ListenerList AST transformation generates code for adding, removing and getting the list of listeners to a class, just by annotating a collection property:
import java.awt.event.ActionListener
import groovy.beans.ListenerList
class Component {
@ListenerList
List<ActionListener> listeners;
}The transform will generate the appropriate add/remove methods based on the generic type of the list. In addition, it will also create fireXXX methods based on the public methods declared on the class:
import java.awt.event.ActionEvent
import java.awt.event.ActionListener as ActionListener
import groovy.beans.ListenerList as ListenerList
public class Component {
@ListenerList
private List<ActionListener> listeners
public void addActionListener(ActionListener listener) {
if ( listener == null) {
return
}
if ( listeners == null) {
listeners = []
}
listeners.add(listener)
}
public void removeActionListener(ActionListener listener) {
if ( listener == null) {
return
}
if ( listeners == null) {
listeners = []
}
listeners.remove(listener)
}
public ActionListener[] getActionListeners() {
Object __result = []
if ( listeners != null) {
__result.addAll(listeners)
}
return (( __result ) as ActionListener[])
}
public void fireActionPerformed(ActionEvent param0) {
if ( listeners != null) {
ArrayList<ActionListener> __list = new ArrayList<ActionListener>(listeners)
for (def listener : __list ) {
listener.actionPerformed(param0)
}
}
}
}@Bindable supports multiple options that will let you further customize the behavior of the transformation:
| Attribute | Default value | Description | Example |
|---|---|---|---|
name |
Generic type name |
By default, the suffix which will be appended to add/remove/… methods is the simple class name of the generic type of the list. |
|
synchronize |
false |
If set to true, generated methods will be synchronized |
|
@groovy.beans.Vetoable
The @Vetoable annotation works in a similar manner to @Bindable but generates constrained property according to the JavaBeans specification, instead of bound properties. The annotation
can be placed on a class, meaning that all properties will be converted to constrained properties, or on a single property. For example, annotating this class with @Vetoable:
import groovy.beans.Vetoable
import java.beans.PropertyVetoException
import java.beans.VetoableChangeListener
@Vetoable
class Person {
String name
int age
}is equivalent to writing this:
public class Person {
private String name
private int age
final private java.beans.VetoableChangeSupport this$vetoableChangeSupport
public void addVetoableChangeListener(VetoableChangeListener listener) {
this$vetoableChangeSupport.addVetoableChangeListener(listener)
}
public void addVetoableChangeListener(String name, VetoableChangeListener listener) {
this$vetoableChangeSupport.addVetoableChangeListener(name, listener)
}
public void removeVetoableChangeListener(VetoableChangeListener listener) {
this$vetoableChangeSupport.removeVetoableChangeListener(listener)
}
public void removeVetoableChangeListener(String name, VetoableChangeListener listener) {
this$vetoableChangeSupport.removeVetoableChangeListener(name, listener)
}
public void fireVetoableChange(String name, Object oldValue, Object newValue) throws PropertyVetoException {
this$vetoableChangeSupport.fireVetoableChange(name, oldValue, newValue)
}
public VetoableChangeListener[] getVetoableChangeListeners() {
return this$vetoableChangeSupport.getVetoableChangeListeners()
}
public VetoableChangeListener[] getVetoableChangeListeners(String name) {
return this$vetoableChangeSupport.getVetoableChangeListeners(name)
}
public void setName(String value) throws PropertyVetoException {
this.fireVetoableChange('name', name, value)
name = value
}
public void setAge(int value) throws PropertyVetoException {
this.fireVetoableChange('age', age, value)
age = value
}
}If the annotation is put on a single property, only that property is made vetoable:
import groovy.beans.Vetoable
class Person {
String name
@Vetoable int age
}2.1.9. Test assistance
@groovy.test.NotYetImplemented
@NotYetImplemented is used to invert the result of a JUnit 3/4 test case. It is in particular useful if a feature is not yet implemented but the test is. In that case, it is expected
that the test fails. Marking it with @NotYetImplemented will inverse the result of the test, like in this example:
import groovy.test.GroovyTestCase
import groovy.test.NotYetImplemented
class Maths {
static int fib(int n) {
// todo: implement later
}
}
class MathsTest extends GroovyTestCase {
@NotYetImplemented
void testFib() {
def dataTable = [
1:1,
2:1,
3:2,
4:3,
5:5,
6:8,
7:13
]
dataTable.each { i, r ->
assert Maths.fib(i) == r
}
}
}Another advantage of using this technique is that you can write test cases for bugs before knowing how to fix them. If some time in the future, a modification in the code fixes a bug by side effect, you’ll be notified because a test which was expected to fail passed.
@groovy.transform.ASTTest
@ASTTest is a special AST transformation meant to help debugging other AST transformations or the Groovy compiler itself. It will let the developer "explore" the AST during compilation and
perform assertions on the AST rather than on the result of compilation. This means that this AST transformations gives access to the AST before the bytecode is produced. @ASTTest can be
placed on any annotable node and requires two parameters:
-
phase: sets at which phase at which
@ASTTestwill be triggered. The test code will work on the AST tree at the end of this phase. -
value: the code which will be executed once the phase is reached, on the annotated node
Compile phase has to be chosen from one of org.codehaus.groovy.control.CompilePhase . However, since it is not possible to annotate a node twice with the same annotation, you will
not be able to use @ASTTest on the same node at two distinct compile phases.
|
value is a closure expression which has access to a special variable node corresponding to the annotated node, and a helper lookup method which will be discussed here.
For example, you can annotate a class node like this:
import groovy.transform.ASTTest
import org.codehaus.groovy.ast.ClassNode
@ASTTest(phase=CONVERSION, value={ (1)
assert node instanceof ClassNode (2)
assert node.name == 'Person' (3)
})
class Person {
}| 1 | we’re checking the state of the Abstract Syntax Tree after the CONVERSION phase |
| 2 | node refers to the AST node which is annotated by @ASTTest |
| 3 | it can be used to perform assertions at compile time |
One interesting feature of @ASTTest is that if an assertion fails, then compilation will fail. Now imagine that we want to check the behavior of an AST transformation at compile time.
We will take @PackageScope here, and we will want to verify that a property annotated with @PackageScope becomes a package private field. For this, we have to know at which phase the
transform runs, which can be found in org.codehaus.groovy.transform.PackageScopeASTTransformation : semantic analysis. Then a test can be written like this:
import groovy.transform.ASTTest
import groovy.transform.PackageScope
@ASTTest(phase=SEMANTIC_ANALYSIS, value={
def nameNode = node.properties.find { it.name == 'name' }
def ageNode = node.properties.find { it.name == 'age' }
assert nameNode
assert ageNode == null // shouldn't be a property anymore
def ageField = node.getDeclaredField 'age'
assert ageField.modifiers == 0
})
class Person {
String name
@PackageScope int age
}The @ASTTest annotation can only be placed wherever the grammar allows it. Sometimes, you would like to test the contents of an AST node which is not annotable. In this case,
@ASTTest provides a convenient lookup method which will search the AST for nodes which are labelled with a special token:
def list = lookup('anchor') (1)
Statement stmt = list[0] (2)| 1 | returns the list of AST nodes which label is 'anchor' |
| 2 | it is always necessary to choose which element to process since lookup always returns a list |
Imagine, for example, that you want to test the declared type of a for loop variable. Then you can do it like this:
import groovy.transform.ASTTest
import groovy.transform.PackageScope
import org.codehaus.groovy.ast.ClassHelper
import org.codehaus.groovy.ast.expr.DeclarationExpression
import org.codehaus.groovy.ast.stmt.ForStatement
class Something {
@ASTTest(phase=SEMANTIC_ANALYSIS, value={
def forLoop = lookup('anchor')[0]
assert forLoop instanceof ForStatement
def decl = forLoop.collectionExpression.expressions[0]
assert decl instanceof DeclarationExpression
assert decl.variableExpression.name == 'i'
assert decl.variableExpression.originType == ClassHelper.int_TYPE
})
void someMethod() {
int x = 1;
int y = 10;
anchor: for (int i=0; i<x+y; i++) {
println "$i"
}
}
}@ASTTest also exposes those variables inside the test closure:
-
nodecorresponds to the annotated node, as usual -
compilationUnitgives access to the currentorg.codehaus.groovy.control.CompilationUnit -
compilePhasereturns the current compile phase (org.codehaus.groovy.control.CompilePhase)
The latter is interesting if you don’t specify the phase attribute. In that case, the closure will be executed after
each compile phase after (and including) SEMANTIC_ANALYSIS. The context of the transformation is kept after each phase,
giving you a chance to check what changed between two phases.
As an example, here is how you could dump the list of AST transformations registered on a class node:
import groovy.transform.ASTTest
import groovy.transform.CompileStatic
import groovy.transform.Immutable
import org.codehaus.groovy.ast.ClassNode
import org.codehaus.groovy.control.CompilePhase
@ASTTest(value={
System.err.println "Compile phase: $compilePhase"
ClassNode cn = node
System.err.println "Global AST xforms: ${compilationUnit?.ASTTransformationsContext?.globalTransformNames}"
CompilePhase.values().each {
def transforms = cn.getTransforms(it)
if (transforms) {
System.err.println "Ast xforms for phase $it:"
transforms.each { map ->
System.err.println(map)
}
}
}
})
@CompileStatic
@Immutable
class Foo {
}And here is how you can memorize variables for testing between two phases:
import groovy.transform.ASTTest
import groovy.transform.ToString
import org.codehaus.groovy.ast.ClassNode
import org.codehaus.groovy.control.CompilePhase
@ASTTest(value={
if (compilePhase == CompilePhase.INSTRUCTION_SELECTION) { (1)
println "toString() was added at phase: ${added}"
assert added == CompilePhase.CANONICALIZATION (2)
} else {
if (node.getDeclaredMethods('toString') && added == null) { (3)
added = compilePhase (4)
}
}
})
@ToString
class Foo {
String name
}| 1 | if the current compile phase is instruction selection |
| 2 | then we want to make sure toString was added at CANONICALIZATION |
| 3 | otherwise, if toString exists and that the variable from the context, added is null |
| 4 | then it means that this compile phase is the one where toString was added |
2.1.10. Grape handling
@groovy.lang.Grapes
Grape is a dependency management engine embedded into Groovy, relying on several annotations which are described
thoroughly in this section of the guide.
2.2. Developing AST transformations
There are two kinds of transformations: global and local transformations.
-
Global transformations are applied to by the compiler on the code being compiled, wherever the transformation apply. Compiled classes that implement global transformations are in a JAR added to the classpath of the compiler and contain service locator file
META-INF/services/org.codehaus.groovy.transform.ASTTransformationwith a line with the name of the transformation class. The transformation class must have a no-args constructor and implement theorg.codehaus.groovy.transform.ASTTransformationinterface. It will be run against every source in the compilation, so be sure to not create transformations which scan all the AST in an expansive and time-consuming manner, to keep the compiler fast. -
Local transformations are transformations applied locally by annotating code elements you want to transform. For this, we reuse the annotation notation, and those annotations should implement
org.codehaus.groovy.transform.ASTTransformation. The compiler will discover them and apply the transformation on these code elements.
2.2.1. Compilation phases guide
Groovy AST transformations must be performed in one of the nine defined compilation phases (org.codehaus.groovy.control.CompilePhase).
Global transformations may be applied in any phase, but local transformations may only be applied in the semantic analysis phase or later. Briefly, the compiler phases are:
-
Initialization: source files are opened and environment configured
-
Parsing: the grammar is used to produce tree of tokens representing the source code
-
Conversion: An abstract syntax tree (AST) is created from token trees.
-
Semantic Analysis: Performs consistency and validity checks that the grammar can’t check for, and resolves classes.
-
Canonicalization: Complete building the AST
-
Instruction Selection: instruction set is chosen, for example Java 6 or Java 7 bytecode level
-
Class Generation: creates the bytecode of the class in memory
-
Output: write the binary output to the file system
-
Finalization: Perform any last cleanup
Generally speaking, there is more type information available later in the phases. If your transformation is concerned with reading the AST, then a later phase where information is more plentiful might be a good choice. If your transformation is concerned with writing AST, then an earlier phase where the tree is more sparse might be more convenient.
2.2.2. Local transformations
Local AST transformations are relative to the context they are applied to. In most cases, the context is defined by an annotation that will define the scope of the transform. For example, annotating a field would mean that the transformation applies to the field, while annotating the class would mean that the transformation applies to the whole class.
As a naive and simple example, consider wanting to write a @WithLogging
transformation that would add console messages at the start and end of a
method invocation. So the following "Hello World" example would
actually print "Hello World" along with a start and stop message:
@WithLogging
def greet() {
println "Hello World"
}
greet()A local AST transformation is an easy way to do this. It requires two things:
-
a definition of the
@WithLoggingannotation -
an implementation of org.codehaus.groovy.transform.ASTTransformation that adds the logging expressions to the method
An ASTTransformation is a callback that gives you access to the
org.codehaus.groovy.control.SourceUnit,
through which you can get a reference to the
org.codehaus.groovy.ast.ModuleNode (AST).
The AST (Abstract Syntax Tree) is a tree structure consisting mostly of org.codehaus.groovy.ast.expr.Expression (expressions) or org.codehaus.groovy.ast.expr.Statement (statements). An easy way to learn about the AST is to explore it in a debugger. Once you have the AST, you can analyze it to find out information about the code or rewrite it to add new functionality.
The local transformation annotation is the simple part. Here is the
@WithLogging one:
import org.codehaus.groovy.transform.GroovyASTTransformationClass
import java.lang.annotation.ElementType
import java.lang.annotation.Retention
import java.lang.annotation.RetentionPolicy
import java.lang.annotation.Target
@Retention(RetentionPolicy.SOURCE)
@Target([ElementType.METHOD])
@GroovyASTTransformationClass(["gep.WithLoggingASTTransformation"])
public @interface WithLogging {
}The annotation retention can be SOURCE because you won’t need the annotation
past that. The element type here is METHOD, the @WithLogging because the annotation
applies to methods.
But the most important part is the
@GroovyASTTransformationClass annotation. This links the @WithLogging
annotation to the ASTTransformation class you will write.
gep.WithLoggingASTTransformation is the fully qualified class name of the
ASTTransformation we are going to write. This line wires the annotation to the transformation.
With this in place, the Groovy compiler is going to invoke
gep.WithLoggingASTTransformation every time an @WithLogging is found in a
source unit. Any breakpoint set within LoggingASTTransformation will now
be hit within the IDE when running the sample script.
The ASTTransformation class is a little more complex. Here is the
very simple, and very naive, transformation to add a method start and
stop message for @WithLogging:
@CompileStatic (1)
@GroovyASTTransformation(phase=CompilePhase.SEMANTIC_ANALYSIS) (2)
class WithLoggingASTTransformation implements ASTTransformation { (3)
@Override
void visit(ASTNode[] nodes, SourceUnit sourceUnit) { (4)
MethodNode method = (MethodNode) nodes[1] (5)
def startMessage = createPrintlnAst("Starting $method.name") (6)
def endMessage = createPrintlnAst("Ending $method.name") (7)
def existingStatements = ((BlockStatement)method.code).statements (8)
existingStatements.add(0, startMessage) (9)
existingStatements.add(endMessage) (10)
}
private static Statement createPrintlnAst(String message) { (11)
new ExpressionStatement(
new MethodCallExpression(
new VariableExpression("this"),
new ConstantExpression("println"),
new ArgumentListExpression(
new ConstantExpression(message)
)
)
)
}
}| 1 | even if not mandatory, if you write an AST transformation in Groovy, it is highly recommended to use CompileStatic
because it will improve performance of the compiler. |
| 2 | annotate with org.codehaus.groovy.transform.GroovyASTTransformation to tell at which compilation phase the transform needs to run. Here, it’s at the semantic analysis phase. |
| 3 | implement the ASTTransformation interface |
| 4 | which only has a single visit method |
| 5 | the nodes parameter is a 2 AST node array, for which the first one is the annotation node (@WithLogging) and
the second one is the annotated node (the method node) |
| 6 | create a statement that will print a message when we enter the method |
| 7 | create a statement that will print a message when we exit the method |
| 8 | get the method body, which in this case is a BlockStatement |
| 9 | add the enter method message before the first statement of existing code |
| 10 | append the exit method message after the last statement of existing code |
| 11 | creates an ExpressionStatement wrapping a MethodCallExpression corresponding to this.println("message") |
It is important to notice that for the brevity of this example, we didn’t make the necessary checks, such as checking
that the annotated node is really a MethodNode, or that the method body is an instance of BlockStatement. This
exercise is left to the reader.
Note the creation of the new println statements in the
createPrintlnAst(String) method. Creating AST for code is not always
simple. In this case we need to construct a new method call, passing in
the receiver/variable, the name of the method, and an argument list.
When creating AST, it might be helpful to write the code you’re trying
to create in a Groovy file and then inspect the AST of that code in the
debugger to learn what to create. Then write a function like
createPrintlnAst using what you learned through the debugger.
In the end:
@WithLogging
def greet() {
println "Hello World"
}
greet()Produces:
Starting greet Hello World Ending greet
| It is important to note that an AST transformation participates directly in the compilation process. A common error by beginners is to have the AST transformation code in the same source tree as a class that uses the transformation. Being in the same source tree in general means that they are compiled at the same time. Since the transformation itself is going to be compiled in phases and that each compile phase processes all files of the same source unit before going to the next one, there’s a direct consequence: the transformation will not be compiled before the class that uses it! In conclusion, AST transformations need to be precompiled before you can use them. In general, it is as easy as having them in a separate source tree. |
2.2.3. Global transformations
Global AST transformation are similar to local one with a major difference: they do not need an annotation, meaning that they are applied globally, that is to say on each class being compiled. It is therefore very important to limit their use to last resort, because it can have a significant impact on the compiler performance.
Following the example of the local AST transformation, imagine that we would like to trace all
methods, and not only those which are annotated with @WithLogging. Basically, we need this code to behave the same
as the one annotated with @WithLogging before:
def greet() {
println "Hello World"
}
greet()To make this work, there are two steps:
-
create the
org.codehaus.groovy.transform.ASTTransformationdescriptor inside theMETA-INF/servicesdirectory -
create the
ASTTransformationimplementation
The descriptor file is required and must be found on classpath. It will contain a single line:
gep.WithLoggingASTTransformationThe code for the transformation looks similar to the local case, but instead of using the ASTNode[] parameter, we need
to use the SourceUnit instead:
@CompileStatic (1)
@GroovyASTTransformation(phase=CompilePhase.SEMANTIC_ANALYSIS) (2)
class WithLoggingASTTransformation implements ASTTransformation { (3)
@Override
void visit(ASTNode[] nodes, SourceUnit sourceUnit) { (4)
def methods = sourceUnit.AST.methods (5)
methods.each { method -> (6)
def startMessage = createPrintlnAst("Starting $method.name") (7)
def endMessage = createPrintlnAst("Ending $method.name") (8)
def existingStatements = ((BlockStatement)method.code).statements (9)
existingStatements.add(0, startMessage) (10)
existingStatements.add(endMessage) (11)
}
}
private static Statement createPrintlnAst(String message) { (12)
new ExpressionStatement(
new MethodCallExpression(
new VariableExpression("this"),
new ConstantExpression("println"),
new ArgumentListExpression(
new ConstantExpression(message)
)
)
)
}
}| 1 | even if not mandatory, if you write an AST transformation in Groovy, it is highly recommended to use CompileStatic
because it will improve performance of the compiler. |
| 2 | annotate with org.codehaus.groovy.transform.GroovyASTTransformation to tell at which compilation phase the transform needs to run. Here, it’s at the semantic analysis phase. |
| 3 | implement the ASTTransformation interface |
| 4 | which only has a single visit method |
| 5 | the sourceUnit parameter gives access to the source being compiled, so we get the AST of the current source
and retrieve the list of methods from this file |
| 6 | we iterate on each method from the source file |
| 7 | create a statement that will print a message when we enter the method |
| 8 | create a statement that will print a message when we exit the method |
| 9 | get the method body, which in this case is a BlockStatement |
| 10 | add the enter method message before the first statement of existing code |
| 11 | append the exit method message after the last statement of existing code |
| 12 | creates an ExpressionStatement wrapping a MethodCallExpression corresponding to this.println("message") |
2.2.4. AST API guide
AbstractASTTransformation
While you have seen that you can directly implement the ASTTransformation interface, in almost all cases you will not
do this but extend the org.codehaus.groovy.transform.AbstractASTTransformation class. This class provides several
utility methods that make AST transformations easier to write. Almost all AST transformations included in Groovy
extend this class.
ClassCodeExpressionTransformer
It is a common use case to be able to transform an expression into another. Groovy provides a class which makes it very easy to do this: org.codehaus.groovy.ast.ClassCodeExpressionTransformer
To illustrate this, let’s create a @Shout transformation that will transform all String constants in method call
arguments into their uppercase version. For example:
@Shout
def greet() {
println "Hello World"
}
greet()should print:
HELLO WORLD
Then the code for the transformation can use the ClassCodeExpressionTransformer to make this easier:
@CompileStatic
@GroovyASTTransformation(phase=CompilePhase.SEMANTIC_ANALYSIS)
class ShoutASTTransformation implements ASTTransformation {
@Override
void visit(ASTNode[] nodes, SourceUnit sourceUnit) {
ClassCodeExpressionTransformer trn = new ClassCodeExpressionTransformer() { (1)
private boolean inArgList = false
@Override
protected SourceUnit getSourceUnit() {
sourceUnit (2)
}
@Override
Expression transform(final Expression exp) {
if (exp instanceof ArgumentListExpression) {
inArgList = true
} else if (inArgList &&
exp instanceof ConstantExpression && exp.value instanceof String) {
return new ConstantExpression(exp.value.toUpperCase()) (3)
}
def trn = super.transform(exp)
inArgList = false
trn
}
}
trn.visitMethod((MethodNode)nodes[1]) (4)
}
}| 1 | Internally the transformation creates a ClassCodeExpressionTransformer |
| 2 | The transformer needs to return the source unit |
| 3 | if a constant expression of type string is detected inside an argument list, transform it into its upper case version |
| 4 | call the transformer on the method being annotated |
AST Nodes
| Writing an AST transformation requires a deep knowledge of the internal Groovy API. In particular it requires knowledge about the AST classes. Since those classes are internal, there are chances that the API will change in the future, meaning that your transformations could break. Despite that warning, the AST has been very stable over time and such a thing rarely happens. |
Classes of the Abstract Syntax Tree belong to the org.codehaus.groovy.ast package. It is recommended to the reader
to use the Groovy Console, in particular the AST browser tool, to gain knowledge about those classes. However, a good
resource for learning is the AST Builder
test suite.
2.2.5. Macros
Introduction
Until version 2.5.0, when developing AST transformations, developers should have a deep knowledge about how the AST (Abstract Syntax Tree) was built by the compiler in order to know how to add new expressions or statements during compile time.
Although the use of org.codehaus.groovy.ast.tool.GeneralUtils static methods could mitigate the burden of creating
expressions and statements, it’s still a low-level way of writing those AST nodes directly.
We needed something to abstract us from writing the AST directly and that’s exactly what Groovy macros were made for.
They allow you to directly add code during compilation, without having to translate the code you had in mind to the
org.codehaus.groovy.ast.* node related classes.
Statements and expressions
Let’s see an example, lets create a local AST transformation: @AddMessageMethod. When applied to a given class it
will add a new method called getMessage to that class. The method will return "42". The annotation is pretty
straight forward:
@Retention(RetentionPolicy.SOURCE)
@Target([ElementType.TYPE])
@GroovyASTTransformationClass(["metaprogramming.AddMethodASTTransformation"])
@interface AddMethod { }What would the AST transformation look like without the use of a macro ? Something like this:
@GroovyASTTransformation(phase = CompilePhase.INSTRUCTION_SELECTION)
class AddMethodASTTransformation extends AbstractASTTransformation {
@Override
void visit(ASTNode[] nodes, SourceUnit source) {
ClassNode classNode = (ClassNode) nodes[1]
ReturnStatement code =
new ReturnStatement( (1)
new ConstantExpression("42")) (2)
MethodNode methodNode =
new MethodNode(
"getMessage",
ACC_PUBLIC,
ClassHelper.make(String),
[] as Parameter[],
[] as ClassNode[],
code) (3)
classNode.addMethod(methodNode) (4)
}
}| 1 | Create a return statement |
| 2 | Create a constant expression "42" |
| 3 | Adding the code to the new method |
| 4 | Adding the new method to the annotated class |
If you’re not used to the AST API, that definitely doesn’t look like the code you had in mind. Now look how the previous code simplifies with the use of macros.
@GroovyASTTransformation(phase = CompilePhase.INSTRUCTION_SELECTION)
class AddMethodWithMacrosASTTransformation extends AbstractASTTransformation {
@Override
void visit(ASTNode[] nodes, SourceUnit source) {
ClassNode classNode = (ClassNode) nodes[1]
ReturnStatement simplestCode = macro { return "42" } (1)
MethodNode methodNode =
new MethodNode(
"getMessage",
ACC_PUBLIC,
ClassHelper.make(String),
[] as Parameter[],
[] as ClassNode[],
simplestCode) (2)
classNode.addMethod(methodNode) (3)
}
}| 1 | Much simpler. You wanted to add a return statement that returned "42" and that’s exactly what you can read inside
the macro utility method. Your plain code will be translated for you to a org.codehaus.groovy.ast.stmt.ReturnStatement |
| 2 | Adding the return statement to the new method |
| 3 | Adding the new code to the annotated class |
Although the macro method is used in this example to create a statement the macro method could also be used to create
expressions as well, it depends on which macro signature you use:
-
macro(Closure): Create a given statement with the code inside the closure. -
macro(Boolean,Closure): if true wrap expressions inside the closure inside a statement, if false then return an expression -
macro(CompilePhase, Closure): Create a given statement with the code inside the closure in a specific compile phase -
macro(CompilePhase, Boolean, Closure): Create a statement or an expression (true == statement, false == expression) in a specific compilation phase.
All these signatures can be found at org.codehaus.groovy.macro.runtime.MacroGroovyMethods
|
Sometimes we could be only interested in creating a given expression, not the whole statement, in order to do that we
should use any of the macro invocations with a boolean parameter:
@GroovyASTTransformation(phase = CompilePhase.INSTRUCTION_SELECTION)
class AddGetTwoASTTransformation extends AbstractASTTransformation {
BinaryExpression onePlusOne() {
return macro(false) { 1 + 1 } (1)
}
@Override
void visit(ASTNode[] nodes, SourceUnit source) {
ClassNode classNode = nodes[1]
BinaryExpression expression = onePlusOne() (2)
ReturnStatement returnStatement = GeneralUtils.returnS(expression) (3)
MethodNode methodNode =
new MethodNode("getTwo",
ACC_PUBLIC,
ClassHelper.Integer_TYPE,
[] as Parameter[],
[] as ClassNode[],
returnStatement (4)
)
classNode.addMethod(methodNode) (5)
}
}| 1 | We’re telling macro not to wrap the expression in a statement, we’re only interested in the expression |
| 2 | Assigning the expression |
| 3 | Creating a ReturnStatement using a method from GeneralUtils and returning the expression |
| 4 | Adding the code to the new method |
| 5 | Adding the method to the class |
Variable substitution
Macros are great but we can’t create anything useful or reusable if our macros couldn’t receive parameters or resolve surrounding variables.
In the following example we’re creating an AST transformation @MD5 that when applied to a given String field will
add a method returning the MD5 value of that field.
@Retention(RetentionPolicy.SOURCE)
@Target([ElementType.FIELD])
@GroovyASTTransformationClass(["metaprogramming.MD5ASTTransformation"])
@interface MD5 { }And the transformation:
@GroovyASTTransformation(phase = CompilePhase.CANONICALIZATION)
class MD5ASTTransformation extends AbstractASTTransformation {
@Override
void visit(ASTNode[] nodes, SourceUnit source) {
FieldNode fieldNode = nodes[1]
ClassNode classNode = fieldNode.declaringClass
String capitalizedName = fieldNode.name.capitalize()
MethodNode methodNode = new MethodNode(
"get${capitalizedName}MD5",
ACC_PUBLIC,
ClassHelper.STRING_TYPE,
[] as Parameter[],
[] as ClassNode[],
buildMD5MethodCode(fieldNode))
classNode.addMethod(methodNode)
}
BlockStatement buildMD5MethodCode(FieldNode fieldNode) {
VariableExpression fieldVar = GeneralUtils.varX(fieldNode.name) (1)
return macro(CompilePhase.SEMANTIC_ANALYSIS, true) { (2)
return java.security.MessageDigest
.getInstance('MD5')
.digest($v { fieldVar }.getBytes()) (3)
.encodeHex()
.toString()
}
}
}| 1 | We need a reference to a variable expression |
| 2 | If using a class outside the standard packages we should add any needed imports or use the qualified name. When using the qualified name of a given static method you need to make sure it’s resolved in the proper compile phase. In this particular case we’re instructing the macro to resolve it at the SEMANTIC_ANALYSIS phase, which is the first compile phase with type information. |
| 3 | In order to substitute any expression inside the macro we need to use the $v method. $v receives a closure as an
argument, and the closure is only allowed to substitute expressions, meaning classes inheriting
org.codehaus.groovy.ast.expr.Expression. |
MacroClass
As we mentioned earlier, the macro method is only capable of producing statements and expressions. But what if we
want to produce other types of nodes, such as a method, a field and so on?
org.codehaus.groovy.macro.transform.MacroClass can be used to create classes (ClassNode instances) in our
transformations the same way we created statements and expressions with the macro method before.
The next example is a local transformation @Statistics. When applied to a given class, it will add two methods
getMethodCount() and getFieldCount() which return how many methods and fields within the class respectively. Here
is the marker annotation.
@Retention(RetentionPolicy.SOURCE)
@Target([ElementType.TYPE])
@GroovyASTTransformationClass(["metaprogramming.StatisticsASTTransformation"])
@interface Statistics {}And the AST transformation:
@CompileStatic
@GroovyASTTransformation(phase = CompilePhase.INSTRUCTION_SELECTION)
class StatisticsASTTransformation extends AbstractASTTransformation {
@Override
void visit(ASTNode[] nodes, SourceUnit source) {
ClassNode classNode = (ClassNode) nodes[1]
ClassNode templateClass = buildTemplateClass(classNode) (1)
templateClass.methods.each { MethodNode node -> (2)
classNode.addMethod(node)
}
}
@CompileDynamic
ClassNode buildTemplateClass(ClassNode reference) { (3)
def methodCount = constX(reference.methods.size()) (4)
def fieldCount = constX(reference.fields.size()) (5)
return new MacroClass() {
class Statistics {
java.lang.Integer getMethodCount() { (6)
return $v { methodCount }
}
java.lang.Integer getFieldCount() { (7)
return $v { fieldCount }
}
}
}
}
}| 1 | Creating a template class |
| 2 | Adding template class methods to the annotated class |
| 3 | Passing the reference class |
| 4 | Extracting reference class method count value expression |
| 5 | Extracting reference class field count value expression |
| 6 | Building the getMethodCount() method using reference’s method count value expression |
| 7 | Building the getFieldCount() method using reference’s field count value expression |
Basically we’ve created the Statistics class as a template to avoid writing low level AST API, then we copied methods created in the template class to their final destination.
Types inside the MacroClass implementation should be resolved inside, that’s why we had to write
java.lang.Integer instead of simply writing Integer.
|
Notice that we’re using @CompileDynamic. That’s because the way we use MacroClass is like we
were actually implementing it. So if you were using @CompileStatic it will complain because an implementation of
an abstract class can’t be another different class.
|
@Macro methods
You have seen that by using macro you can save yourself a lot of work but you might wonder where
that method came from. You didn’t declare it or static import it. You can think of it as a special
global method (or if you prefer, a method on every Object). This is much like how the println
extension method is defined. But unlike println which becomes a method selected for execution
later in the compilation process, macro expansion is done early in the compilation process.
The declaration of macro as one of the available methods for this early expansion is done
by annotating a macro method definition with the @Macro annotation and making that method
available using a similar mechanism for extension modules. Such methods are known as macro methods
and the good news is you can define your own.
To define your own macro method, create a class in a similar way to an extension module and add a method such as:
public class ExampleMacroMethods {
@Macro
public static Expression safe(MacroContext macroContext, MethodCallExpression callExpression) {
return ternaryX(
notNullX(callExpression.getObjectExpression()),
callExpression,
constX(null)
);
}
...
}Now you would register this as an extension module using a org.codehaus.groovy.runtime.ExtensionModule
file within the META-INF/groovy directory.
Now, assuming that the class and meta info file are on your classpath, you can use the macro method in the following way:
def nullObject = null
assert null == safe(safe(nullObject.hashcode()).toString())2.2.6. Testing AST transformations
Separating source trees
This section is about good practices in regard to testing AST transformations. Previous sections highlighted the fact that to be able to execute an AST transformation, it has to be precompiled. It might sound obvious but a lot of people get caught on this, trying to use an AST transformation in the same source tree as where it is defined.
The first tip for testing AST transformation is therefore to separate test sources from the sources of the transform. Again, this is nothing but best practices, but you must make sure that your build too does actually compile them separately. This is the case by default with both Apache Maven and Gradle.
Debugging AST transformations
It is very handy to be able to put a breakpoint in an AST transformation, so that you can debug your code in the IDE. However, you might be surprised to see that your IDE doesn’t stop on the breakpoint. The reason is actually simple: if your IDE uses the Groovy compiler to compile the unit tests for your AST transformation, then the compilation is triggered from the IDE, but the process which will compile the files doesn’t have debugging options. It’s only when the test case is executed that the debugging options are set on the virtual machine. In short: it is too late, the class has been compiled already, and your transformation is already applied.
A very easy workaround is to use the GroovyTestCase class which provides an assertScript method. This means that
instead of writing this in a test case:
static class Subject {
@MyTransformToDebug
void methodToBeTested() {}
}
void testMyTransform() {
def c = new Subject()
c.methodToBeTested()
}You should write:
void testMyTransformWithBreakpoint() {
assertScript '''
import metaprogramming.MyTransformToDebug
class Subject {
@MyTransformToDebug
void methodToBeTested() {}
}
def c = new Subject()
c.methodToBeTested()
'''
}The difference is that when you use assertScript, the code in the assertScript block is compiled when the
unit test is executed. That is to say that this time, the Subject class will be compiled with debugging active, and
the breakpoint is going to be hit.
ASTMatcher
Sometimes you may want to make assertions over AST nodes; perhaps to filter the nodes, or to make sure a given transformation has built the expected AST node.
Filtering nodes
For instance if you would like to apply a given transformation only to a specific set of AST nodes, you could
use ASTMatcher to filter these nodes. The following example shows how to transform a given expression to
another. Using ASTMatcher it looks for a specific expression 1 + 1 and it transforms it to 3. That’s why
we called it the @Joking example.
First we create the @Joking annotation that only can be applied to methods:
@Retention(RetentionPolicy.SOURCE)
@Target([ElementType.METHOD])
@GroovyASTTransformationClass(["metaprogramming.JokingASTTransformation"])
@interface Joking { }Then the transformation, that only applies an instance of org.codehaus.groovy.ast.ClassCodeExpressionTransformer
to all the expressions within the method code block.
@CompileStatic
@GroovyASTTransformation(phase = CompilePhase.INSTRUCTION_SELECTION)
class JokingASTTransformation extends AbstractASTTransformation {
@Override
void visit(ASTNode[] nodes, SourceUnit source) {
MethodNode methodNode = (MethodNode) nodes[1]
methodNode
.getCode()
.visit(new ConvertOnePlusOneToThree(source)) (1)
}
}| 1 | Get the method’s code statement and apply the expression transformer |
And this is when the ASTMatcher is used to apply the transformation only to those expressions matching
the expression 1 + 1.
class ConvertOnePlusOneToThree extends ClassCodeExpressionTransformer {
SourceUnit sourceUnit
ConvertOnePlusOneToThree(SourceUnit sourceUnit) {
this.sourceUnit = sourceUnit
}
@Override
Expression transform(Expression exp) {
Expression ref = macro { 1 + 1 } (1)
if (ASTMatcher.matches(ref, exp)) { (2)
return macro { 3 } (3)
}
return super.transform(exp)
}
}| 1 | Builds the expression used as reference pattern |
| 2 | Checks the current expression evaluated matches the reference expression |
| 3 | If it matches then replaces the current expression with the expression built with macro |
Then you could test the implementation as follows:
package metaprogramming
class Something {
@Joking
Integer getResult() {
return 1 + 1
}
}
assert new Something().result == 3Unit testing AST transforms
Normally we test AST transformations just checking that the final use of the transformation does what we expect. But it would be great if we could have an easy way to check, for example, that the nodes the transformation adds are what we expected from the beginning.
The following transformation adds a new method giveMeTwo to an annotated class.
@GroovyASTTransformation(phase = CompilePhase.INSTRUCTION_SELECTION)
class TwiceASTTransformation extends AbstractASTTransformation {
static final String VAR_X = 'x'
@Override
void visit(ASTNode[] nodes, SourceUnit source) {
ClassNode classNode = (ClassNode) nodes[1]
MethodNode giveMeTwo = getTemplateClass(sumExpression)
.getDeclaredMethods('giveMeTwo')
.first()
classNode.addMethod(giveMeTwo) (1)
}
BinaryExpression getSumExpression() { (2)
return macro {
$v{ varX(VAR_X) } +
$v{ varX(VAR_X) }
}
}
ClassNode getTemplateClass(Expression expression) { (3)
return new MacroClass() {
class Template {
java.lang.Integer giveMeTwo(java.lang.Integer x) {
return $v { expression }
}
}
}
}
}| 1 | Adding the method to the annotated class |
| 2 | Building a binary expression. The binary expression uses the same variable expression in both
sides of the + token (check varX method at org.codehaus.groovy.ast.tool.GeneralUtils). |
| 3 | Builds a new ClassNode with a method called giveMeTwo which returns the result of an expression
passed as parameter. |
Now instead of creating a test executing the transformation over a given sample code. I would like to check that the construction of the binary expression is done properly:
void testTestingSumExpression() {
use(ASTMatcher) { (1)
TwiceASTTransformation sample = new TwiceASTTransformation()
Expression referenceNode = macro {
a + a (2)
}.withConstraints { (3)
placeholder 'a' (4)
}
assert sample
.sumExpression
.matches(referenceNode) (5)
}
}| 1 | Using ASTMatcher as a category |
| 2 | Build a template node |
| 3 | Apply some constraints to that template node |
| 4 | Tells compiler that a is a placeholder. |
| 5 | Asserts reference node and current node are equal |
Of course you can/should always check the actual execution:
void testASTBehavior() {
assertScript '''
package metaprogramming
@Twice
class AAA {
}
assert new AAA().giveMeTwo(1) == 2
'''
}ASTTest
Last but not least, testing an AST transformation is also about testing the state of the AST during compilation. Groovy
provides a tool named @ASTTest for this: it is an annotation that will let you add assertions on an abstract syntax
tree. Please check the documentation for ASTTest for more details.
2.2.7. External references
If you are interested in a step-by-step tutorial about writing AST transformations, you can follow this workshop.